User-defined functions
Introduction
User-defined functions are functions written by programmers, as opposed to the built-in functions provided by Pine Script®. They help to encapsulate custom calculations that scripts perform conditionally or repeatedly, or to isolate logic in a single location for modularity and readability. Programmers often write functions to extend the capabilities of their scripts when no existing built-ins fit their needs.
A function definition consists of two main parts: a header and a body.
Header
f()). If the function has declared parameters, calls to the function list arguments (values or references) for those parameters within the parentheses (e.g., f(x = 1)).
Body
Function definitions in Pine can use either of the following formats:
- Single-line format, where the function’s header and body occupy only one line of code. This format is best suited for defining compact functions containing only minimal statements or expressions.
- Multiline format, where the first line defines the function’s header, and all indented lines that follow define the function’s body. This format is optimal for functions that require conditional structures, loops, or multiple other statements.
Programmers can define functions for use only in a specific script, or create library functions for use in other scripts. Refer to our Style guide for recommendations on where to include function definitions in a source code. To learn more about library functions and their unique requirements, see the Libraries page.
Regardless of format, location, or use, several common characteristics and limitations apply to every user-defined function, including the following:
- The function’s definition must be in the global scope. Programmers cannot define functions inside the body of another function or the local blocks of any other structure.
- The function cannot modify its declared parameters or any global variables.
- The function can include calls to most other functions within its body, but it cannot include calls to itself or to functions that must be called from the global scope.
- Each written call to the function must have consistent parameter types, and therefore consistent argument types, across all executions.
- Each call returns the result of evaluating the final statement or separate expression defined in the function’s body, and that result inherits the strongest type qualifier used in the call’s calculations. As with parameter types, the call’s returned types must be consistent across executions.
- Each written call to the function establishes a new scope from the function’s definition. The parameters, variables, and expressions created in that scope are unique and have an independent history; other calls to the function do not directly affect them.
Structure and syntax
A function definition can occupy a single line of code or multiple lines, depending on the expressions and statements that the function requires. The single-line and multiline formats are similar, with the key difference being the placement of the function’s body.
Single-line functions define their header and body on the same line of code:
<functionHeader> => <functionBody>In contrast, multiline functions define the body on separate lines of code following the header. The code block following the header line has an indentation of four spaces or a single tab:
<functionHeader> => <functionBody>Both formats use the following syntax for defining the function’s header:
[export ]<functionName>([[[paramQualifier ]<paramType> ]<paramName>[ = defaultValue], …]) =>Where:
- All parts within square brackets (
[]) represent optional syntax, and all parts within angle brackets (<>) represent required syntax. - export is the optional keyword for exporting the function from a library, enabling its use in other scripts. See the Libraries page to learn more.
functionNameis the function’s identifier (name). The script calls the function by referencing this identifier, followed by parentheses.paramNameis the identifier for a declared parameter. The script can supply a specific argument (value or reference) to the parameter in each function call. A function header can contain zero or more parameter declarations.defaultValueis the parameter’s default argument. If not specified, each call to the function requires an argument for the parameter. Otherwise, supplying an argument is optional.paramQualifierandparamTypeare qualifier and type keywords, which together specify the parameter’s qualified type. Using these keywords is optional in most cases. If the declaration does not include them, the compiler determines the parameter’s type information automatically. See the Declaring parameter types section to learn more.
Below is an example of a simple function header. The header declares that the function’s name is myFunction, and that the function has two parameters named param1 and param2:
Note that:
- Neither parameter has a default argument. Therefore, the script must supply arguments to these parameters in every
myFunction()call. - Because the function’s parameters do not include type keywords, they inherit the same qualified type as their argument in each separate call.
The following two sections explain the body structure of single-line and multiline functions.
Single-line functions
A single-line function’s body begins and ends on the same line of code as the header. This format is convenient for defining compact functions that execute only simple statements and do not use conditional structures or loops. The syntax to define a single-line function is as follows:
<functionHeader> => {statement, }<returnExpression>Where:
functionHeaderdeclares the function’s name and parameters, as explained in the previous section.statement, in curly brackets, represents zero or more statements or expressions that the function evaluates before returning a result. The function must separate all individual statements in its body with commas.returnExpressionis the final expression, variable, or tuple in the function’s body. Each function call returns the result of evaluating this code.
The following example defines an add() function in single-line format. The function includes two parameters named val1 and val2. The body of the function contains a single + operation that adds or concatenates the parameter values, depending on their types. Each call to the function returns the result of that operation:
A script that includes this function definition can call add() with different arguments for val1 and val2. The type of value returned by each call depends on these arguments. For example, the script below executes a few calls to add(), then passes their results to the series, title, and linewidth parameters in a call to plot():
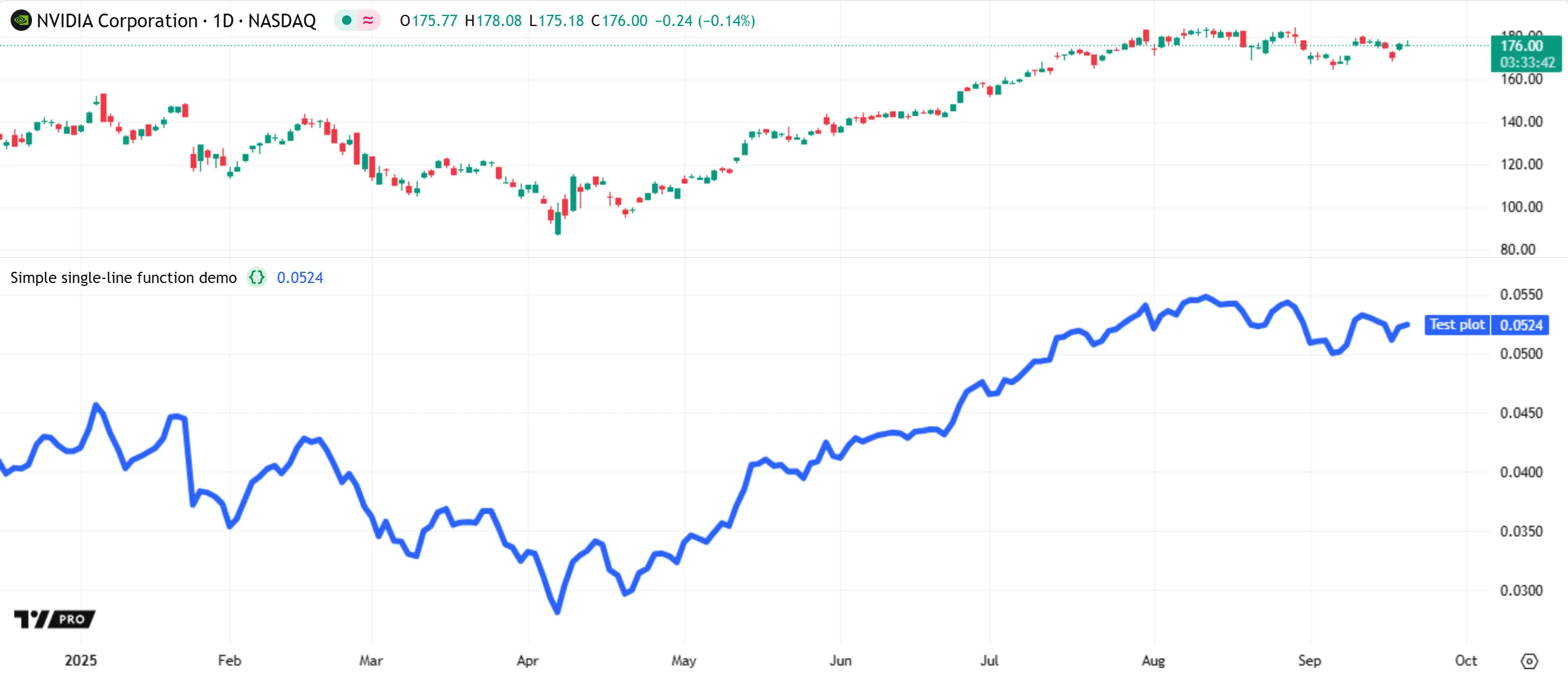
Note that:
- The
val1andval2parameters automatically inherit the qualified types of their arguments in eachadd()call, because the function’s header does not declare their types using type and qualifier keywords. - Although the parameters accept arguments of any type, except for void, an
add()function call compiles successfully only if the arguments have types that are compatible with the + operator, such as “int”, “float”, or “string”. As shown above, if the arguments are numbers (“int” or “float” values), the function performs addition. If they are strings, the function performs concatenation. - The value returned by each
add()call inherits the strongest type qualifier used in the calculation. The first two calls return “series” results because both use at least one “series” value. In contrast, the other calls return “const” results, because all values in their calculations are constants.
The body of a single-line function can contain a comma-separated list of statements and expressions. Each call to the function evaluates the list from left to right, treating each item as a separate line of code. The call returns the result of evaluating the final expression or statement in the list.
For example, the following script contains a zScore() function defined in single-line format. The function computes the z-score of a source series over length bars. Its body declares two variables, mean and sd, to hold the average and standard deviation of the series. The final expression in the body uses these variables to calculate the function’s returned value. On each bar, the script calls the zScore() function using close as the source argument and 20 as the length argument, then plots the result:
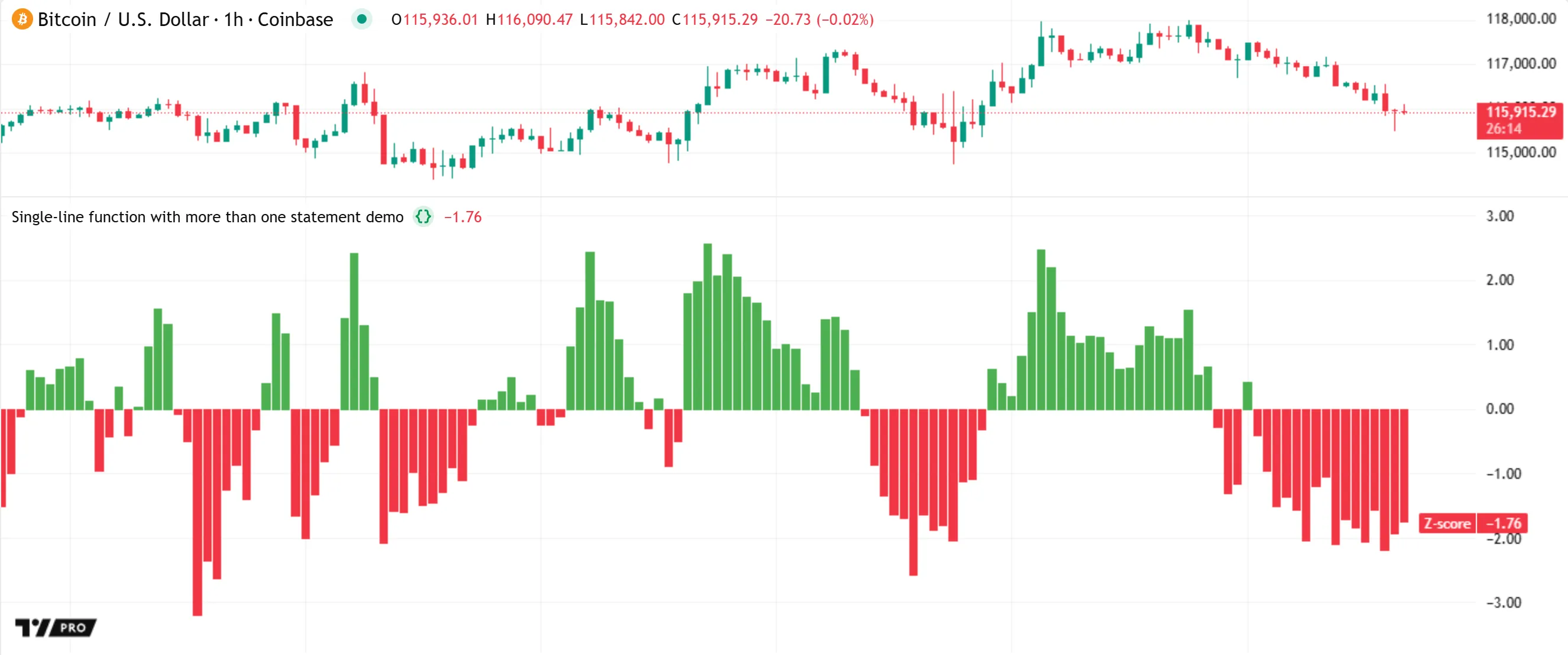
Note that:
- The
sourceparameter requires an “int” or “float” value because its declaration includes the float keyword. Thelengthparameter requires an “int” value because its declaration uses the int keyword. See the Declaring parameter types section to learn more. - The
//@variableand//@functioncomments are annotations that document identifiers in the code. The//@functionannotation provides documentation for thezScore()function. Users can hover over the function’s name in the Pine Editor, or write a function call, to view the annotation’s formatted text in a pop-up window. See the Documenting functions section for more information.
Multiline functions
A multiline function defines its body using a block of code following the header line. The general syntax is as follows:
<functionHeader> => [statements] … <returnExpression>Where:
functionHeaderdeclares the function’s name and parameters. See the Structure and syntax section above to learn the syntax for function headers.statementsis an optional block of statements and expressions that the function evaluates before returning a result. Single lines in the body can also contain multiple statements separated by commas.returnExpressionis the final statement, expression, variable, or tuple at the end of the body. Each call to the function returns the result of this code. If the end of the function’s body is a comma-separated list of statements or expressions,returnExpressionis the code at the end of that list. If the final statement is a conditional structure or loop, the function returns that structure’s result.- Each line of code following the function’s header has an indentation of four spaces or a tab, signifying that it belongs to the function’s scope. The function’s body ends on the final indented line; all non-indented code following the definition belongs to the global scope.
The multiline format is well-suited for defining functions that perform multiple tasks. Programmers can organize all the function’s statements across different lines and document them with comments for readability.
In the following example, we modified the second script from the Single-line functions section to define an equivalent zScore() function using the multiline format. The function’s variable declarations and return expression are now on separate indented lines, and we’ve added comments inside the body to describe the function’s calculations:
Note that:
- We added the float keyword to the
meanandsddeclarations to declare their types in the code. The keyword is optional in both variable declarations because the compiler can determine the correct types from the assigned values, but including it helps promote readability.
Programmers often define multiline functions to encapsulate complex or logical tasks involving loops or conditional structures. If the final part of a function’s body contains one of these structures, a call to the function returns the result of evaluating that structure.
For example, the smoothMedian() function in the script below calculates the median of a source series over length bars, then smooths the result using a moving average specified by the avgType parameter. The function compares the avgType value in a switch statement to select the type of average that it returns. The script calls the function to calculate the median of close values over 10 bars, smoothed by an EMA with the same length, and then plots the result on the chart:
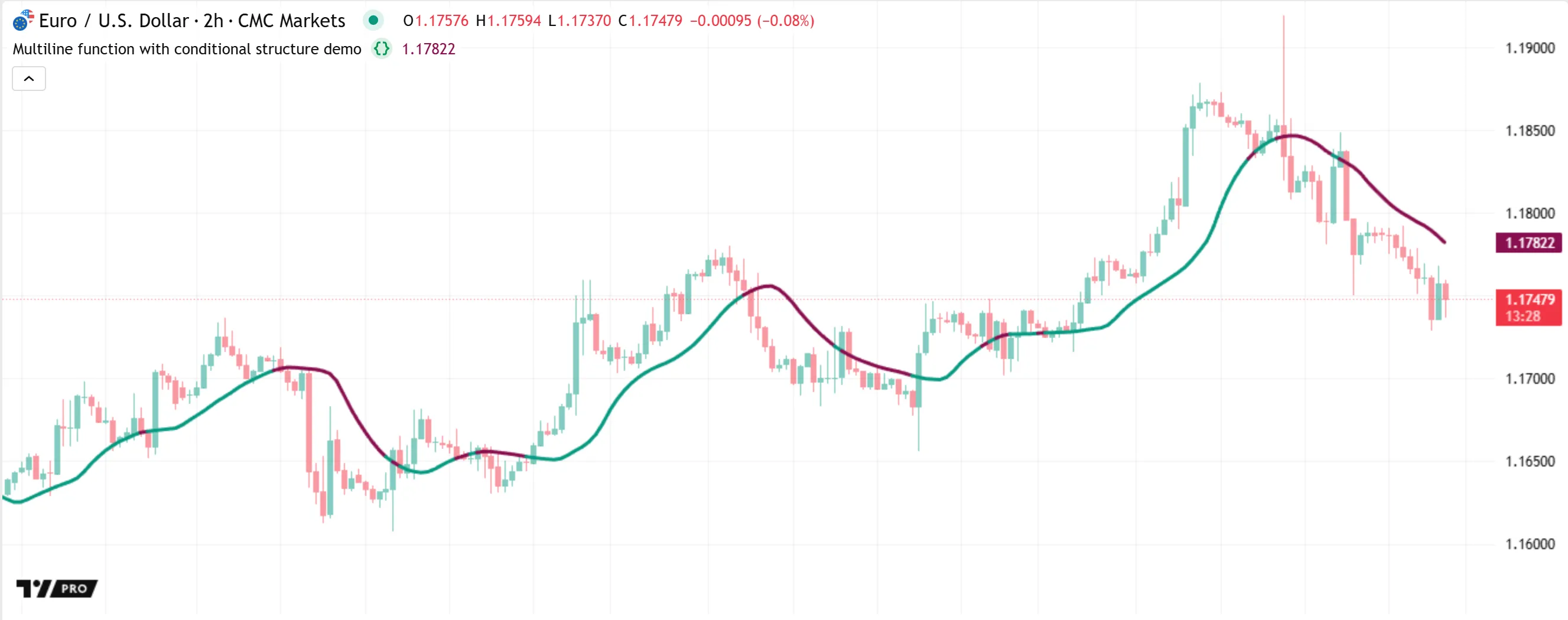
Note that:
- The
smoothMedian()call in this example does not supply an argument to theavgTypeparameter. Specifying an argument is optional, because the parameter declaration includes a default argument ("ema"). - We included empty lines between each section for readability. The lines that follow an empty line are considered part of the function as long as they are indented correctly.
Functions that return multiple results
Sometimes, a function must perform multiple calculations and return separate results for each one. Programmers can write functions that return multiple values or references by using a tuple as the final statement in the function’s body. A tuple is a comma-separated list of expressions enclosed in square brackets ([]). Every call to a function with a tuple at the end of its body returns the result of evaluating each listed expression in order.
For example, the sumDiff() function below calculates both the sum and difference of the values passed to its val1 and val2 parameters. Its body consists of a two-item tuple containing the addition and subtraction operations:
Note that:
- The
val1andval2parameters include the float keyword in their declarations. Therefore, both parameters are of the type “float”, and they accept only “float” or “int” arguments. See the Declaring parameter types section for more information.
Because the end of the function’s body is a two-item tuple, each call to the function always returns two separate values. To assign the function’s results to variables, the script must use a tuple declaration containing one new variable for each returned item. It is not possible to reassign existing tuples or to use previously declared variables within them.
The following example calls sumDiff() to calculate the sum and difference between two pseudorandom values. The script uses a tuple declaration containing two variables, sum and diff, to store the values returned by the call. Then, it plots the values of those variables on the chart:
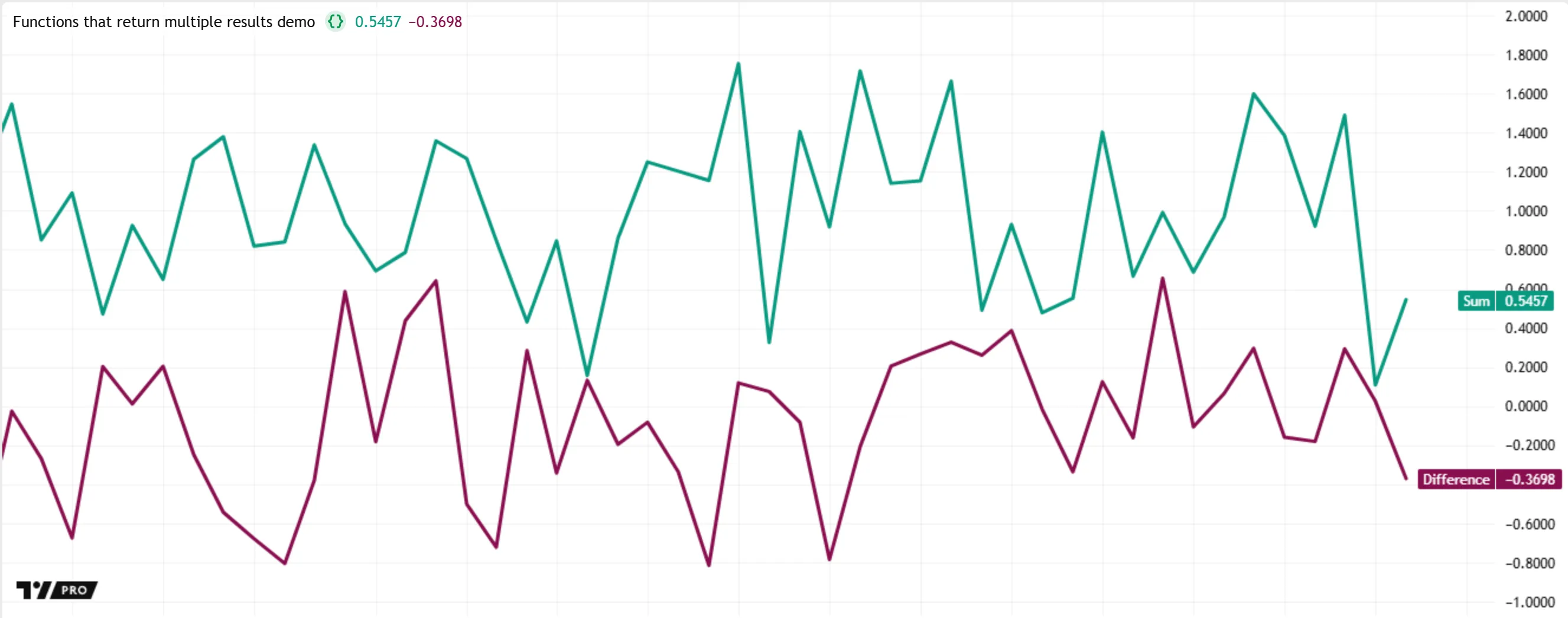
In some cases, a script might not require all the results from the tuple returned by a function call. Instead of writing unique identifiers for every variable in the tuple declaration, programmers can use an underscore as the identifier for each variable that the script does not require. All variables with the name _ are not usable in the script’s calculations.
For example, if we change sum to _ in the previous script’s tuple declaration, the first value returned by the sumDiff() call is inaccessible to the script. Attempting to use the identifier elsewhere in the code causes a compilation error, as shown by the first plot() call in the script version below:
Declaring parameter types
User-defined function definitions can prefix each parameter declaration with type and qualifier keywords, enabling strict control over the qualified types that a script can pass to the parameter in any function call. If a declaration does not include these keywords, the compiler automatically determines the parameter’s qualified type based on its arguments and the function’s structure.
The sections below explain how type and qualifier keywords affect the behavior of function parameters. For detailed information about Pine’s types and qualifiers, refer to the Type system page.
Type keywords
Parameter declarations prefixed by type keywords — such as int, float, string, or label — declare the types of data that the parameters represent in any function call. If a parameter declaration includes a type keyword, it accepts only arguments of that type, or arguments that Pine can automatically cast to that type.
If a function parameter does not have a type keyword in its declaration, its type is initially undefined. In each separate call to the function, the parameter automatically inherits the same type as its specified argument. In other words, the parameter can take on any type, except for void, depending on the function call.
The following example demonstrates this behavior. The user-defined pass() function in the script below returns the value of the source parameter without performing additional calculations. The parameter’s declaration does not include a type keyword. The script executes five calls to the function with different argument types and then uses their results in code that accepts those types. This script compiles successfully, because each call’s version of the source parameter inherits its argument’s type:
We can restrict the source parameter’s type, and thus the arguments it can accept, by including a type keyword in its declaration. For example, in the modified script below, we added the int keyword to the declaration to specify that the parameter’s type is “int”. With this change, the last three pass() calls now cause a compilation error, because the parameter no longer allows “string”, “color”, or “plot_display” arguments:
Note that:
- If a parameter declaration includes a type keyword without a qualifier keyword, such as const or simple, the compiler automatically sets the qualifier to “series” or “simple”, depending on the function’s calculations. In this example, the
sourceparameter’s type is “series int”, because the function’s logic does not require a “simple” or weaker qualifier. See the Qualifier keywords section to learn more.
In most cases, type keywords are optional in parameter declarations. However, specifying a parameter’s type is required if:
- The parameter’s default argument is an
navalue. - The parameter declaration includes a qualifier keyword.
- The function definition includes the export keyword. Exported functions require declared types for every parameter. See the Libraries page to learn more.
- The function definition includes the method keyword, and the parameter is the first one listed in the header. See the User-defined methods section of the Methods page for more information.
Qualifier keywords
A qualifier keyword (const, simple, or series) preceding a type keyword in a parameter declaration specifies the parameter’s type qualifier. The keyword also indicates when the argument for the parameter must be accessible, and whether that argument can change across bars:
const
simple
series
Qualifier keywords are always optional in parameter declarations. If a declaration does not include a qualifier keyword, the compiler uses the following logic to assign a qualifier to the parameter:
- If the declaration does not include a type keyword, the compiler assigns the parameter the same qualifier and type as its argument in each written function call. For example, if the script passes a “const int” argument in one function call, the parameter of that call inherits the type “const int”. If it uses a “series float” value in another call to the function, the parameter of that call inherits the type “series float”.
- If the declaration does include a type keyword, the compiler first tests whether the parameter can use the “series” qualifier. If the function contains a call to another function in its body, and that call cannot accept a “series” value, the compiler then checks whether the “simple” qualifier works. If neither the “series” nor “simple” qualifier is compatible with the function’s calculations, a compilation error occurs.
To demonstrate these behaviors, let’s revisit the pass() function from the Type keywords section. The function returns the value of its source parameter without additional calculations. If the parameter does not include any keywords in its declaration, its qualified type is that of its argument in each separate function call:
The script below calls pass() using an “int” value with the “const” qualifier, then uses the returned value as the length argument in a call to ta.ema() and plots the result. This script compiles successfully because our pass() call returns the same qualified type as its argument (“const int”), and the length parameter of ta.ema() can accept a value of that type:
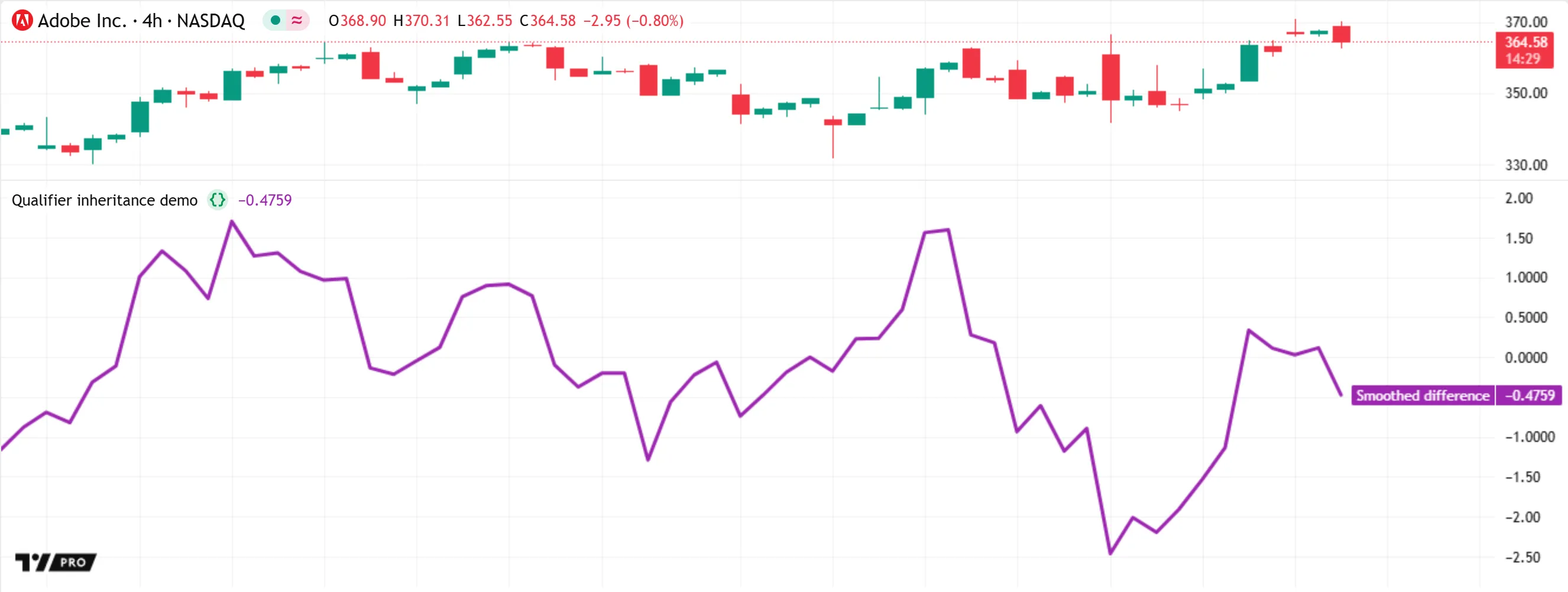
If we add int to the source declaration, the parameter then requires an “int” value, but it does not directly inherit the same type qualifier as its argument. Instead, the compiler first checks if it can assign “series” to the parameter, then tries using “simple” if “series” does not work.
Our pass() function does not use the source parameter in any local function calls that require a “simple int” value, so the compiler sets its qualifier to “series”. Consequently, the function’s returned type is always “series int”, even if the source argument is a “const” value. Adding this change to the previous script thus causes a compilation error, because the length parameter of ta.ema() cannot accept a “series” argument; only “simple” or weaker qualifiers are allowed:
We can restrict the type qualifier of our function’s source parameter by adding a qualifier keyword to its declaration. In the script version below, we prefixed the declaration with the simple keyword. Now, the source parameter’s type is “simple int” instead of “series int”. With this change, the script does not cause an error, because the pass() function’s returned type is now compatible with the length parameter of ta.ema():
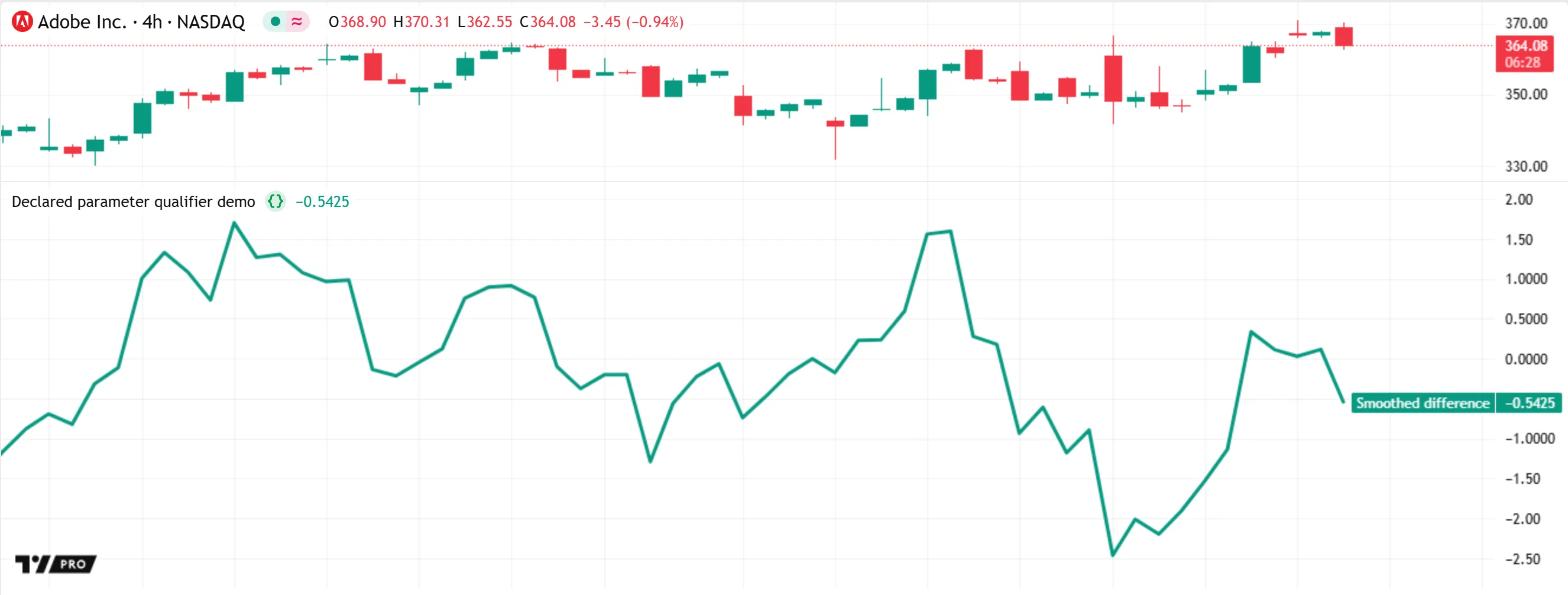
For some types of calculations, using “series” values might not cause a compilation error, but if the values do not remain consistent across all bars, the calculations produce incorrect or unintended results. When wrapping such calculations in a function, declaring the relevant parameters with the simple keyword — or const when appropriate — ensures that only unchanging arguments are allowed in each call, preventing unintended behavior.
Let’s look at an example. The following calcAvg() function calculates a moving average of a source series over length bars. The function compares the value of its avgType parameter in a switch statement to select a built-in ta.*() call to use for the average calculation:
The compiler raises a warning about this function’s structure inside the Pine Editor, because using calcAvg() with a dynamic avgType argument can cause unintended results. If the ta.*() call executed by the function changes on any bar, it affects the history of values used in the average calculations. See the Time series in scopes section of the Execution model page for advanced details about this behavior.
The script below executes two calcAvg() calls and plots their returned values. The first call consistently uses "ema" as its avgType argument, and the other alternates between using "ema" and "sma" as the argument. The second call’s result does not often align with the first call’s result, even on the bars where its avgType argument is "ema", because both ta.*() calls require consistent evaluation to calculate the averages for consecutive bars:
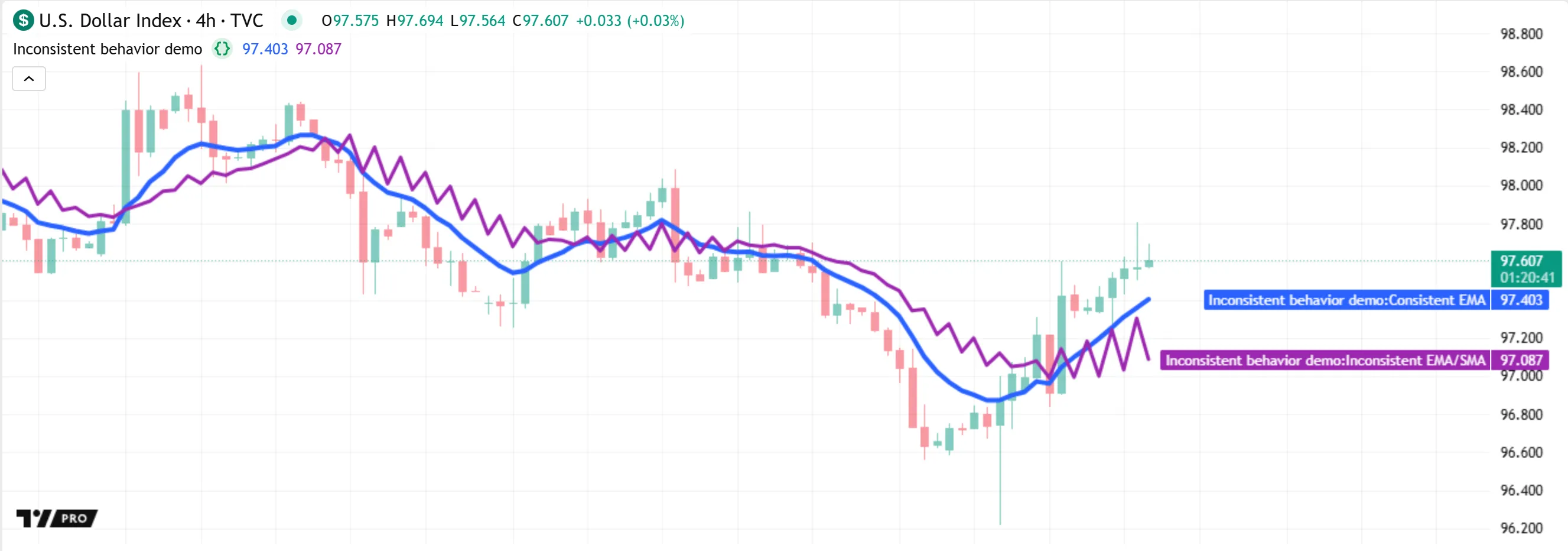
To ensure that any calcAvg() call calculates consistent averages without modifying the function’s logic, we can prevent it from using dynamic avgType arguments by prefixing the parameter declaration with the simple keyword. With this change, the compiler does not raise a warning about the function — as long as the script evaluates calls to the function on every bar — because any calcAvg() call must always use the same ta.*() function. Now, if the script attempts to pass a “series string” value to avgType, a compilation error occurs:
Documenting functions
Pine Script features annotations that programmers can use to document a function, its parameters, and its result directly in the source code. Annotations are comments that issue special instructions to the compiler or the Pine Editor. The editor can display the formatted text from function annotations in a pop-up window as users work with the function in their code. Additionally, the “Publish script” window uses the text from function annotations to generate default descriptions for libraries.
To annotate a function, add comment lines containing valid annotation syntax directly above the function’s header. Each annotation comment must start with @, immediately followed by the keyword that indicates its purpose. Below is the syntax for all annotations that apply exclusively to function and method definitions:
//@function <description>
description text in its pop-up window while the user hovers over the function’s name or writes a function call.
//@param <parameterName> <description>
description text beneath the parameter’s type in its pop-up window while the user writes an argument for that parameter in a function call.
parameterName is the name of one of the function’s parameters. If the annotation does not include a parameter name, or if the specified name does not match one of the listed parameters, the annotation is ignored.
//@returns <description>
description text at the bottom of the pop-up window that appears while the user hovers over the function’s name.
The following code block defines a mixEMA() function, which calculates an EMA of a source series and then mixes the EMA with that series by a specified amount (mix). Above the function definition, we included //@function, //@param, and //@returns annotations to document its purpose, parameters, and result, respectively. Users can view the formatted text from these annotations by hovering over the mixEMA identifier in the Pine Editor or writing a mixEMA() function call:
Note that:
- The pop-up window that shows annotation text automatically removes most leading or repeated whitespaces in its formatted result.
The description attached to any function annotation can occupy more than one comment line in the source code, but only if there are no blank lines between each comment line. For example, the following code block contains //@function and //@param annotations that both define descriptions across three comment lines:
Note that each separate comment line in an annotation block does not typically create a new line of text in the displayed description. Programmers can create annotations with multiline descriptions by adding empty comment lines to the annotation block. For example:
Annotations support a limited range of Markdown syntax, which enables custom text formats in the Pine Editor’s pop-up window. The example below shows some of the syntax that the window can render. To view the annotation’s results, copy the code and hover over the f identifier inside the Pine Editor:
Function scopes
All variables, expressions, and statements have a designated scope, which refers to the part of the script where they are defined and accessible. Every script has one global scope and zero or more local scopes.
Each function definition creates a distinct local scope. All code written in the function’s header and body belongs exclusively to that definition; no code outside the function can access its declared variables or parameters.
For example, the following script defines a function named myFun(). The function’s body contains a variable named result. The script attempts to use a plot() call, in the global scope, to display the value of that variable. This script causes a compilation error, because the global scope cannot access the function’s local identifiers, and there is no global variable named result:
The only way for the script to use the function’s code is to execute a function call. Additionally, because the code in the function definition is inaccessible to other scopes, the script can declare separate variables in other parts of the code with the same identifiers as the function’s local variables and parameters. For example, the following script executes a call to the myFun() function and assigns its returned value to a new, global variable also named result. The plot() call in this script does not cause an error, because only the global result variable is available to that call:
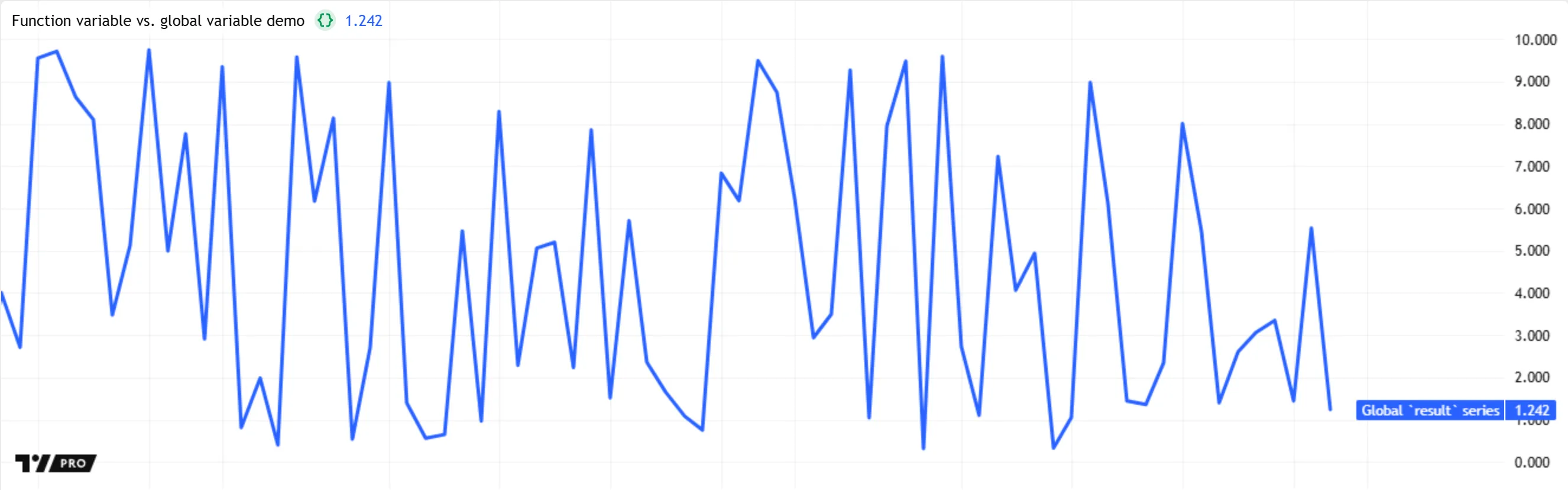
All local scopes in a script, including the scope of a function definition, are embedded into the script’s global scope. Therefore, while the global scope cannot access any variables within a function’s scope, the function can access any global variables declared above its definition.
For instance, the following script declares a globalVar variable before defining the myFun() function, then uses that variable in the function’s body. This script compiles successfully, because the function definition has access to any global variables declared before its location in the code:
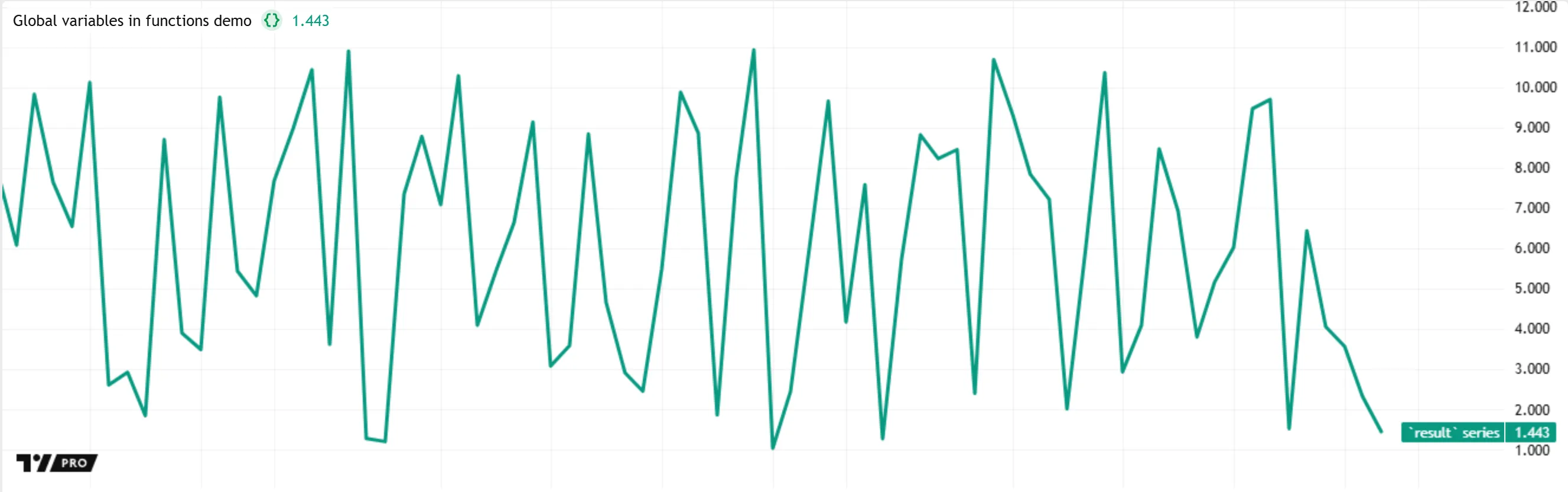
It’s important to note that all global variables used in a function’s body cannot change their assigned values or references during any execution of a function call. Therefore, although user-defined functions can access some global variables, they cannot modify those variables using the reassignment or compound assignment operators. Similarly, a function cannot reassign its declared parameters, because the parameters of each function call must always hold the same values or references passed to them from the scope where that call occurs.
The example script below demonstrates this limitation. It declares a global variable named counter with an initial value of 0. Then, it defines an increment() function that uses the += operator to change the counter variable’s assigned value, causing a compilation error:
Scope of a function call
A function’s definition acts as a template for each function call. Every call written in the source code establishes a separate local scope using that definition. The parameters, variables, and expressions created for each function call are unique to that call, and they leave independent historical trails in the script’s time series. Because each written call has a separate scope, with an independent history, no two calls to the same function directly affect each other.
For example, the script below contains a user-defined function named accumulate(). The function’s structure declares a persistent variable named total with an initial value of 0, then adds the value of its source parameter to that variable and returns the result. The script uses two separate accumulate() calls inside a ternary operation, and then plots the result returned by that expression. The operation triggers the first written call on every third bar, and the second on all other bars. Both calls use a value of 1 as their source argument:
Note that:
- The
totalvariable and its assigned value persist across bars because the variable declaration includes the var keyword. See the Declaration modes section of the Variable declarations page to learn more.
Both accumulate() calls in this script might seem identical. However, each one has a separate scope with distinct versions of the source parameter and the total variable. The first call does not affect the second, and vice versa. As shown below, the script’s plotted value decreases on every third bar before increasing again on subsequent bars. This behavior occurs because each accumulate() call’s version of total increases its value only on bars where the script evaluates that call, and the script evaluates the first call on about half as many bars as the second:
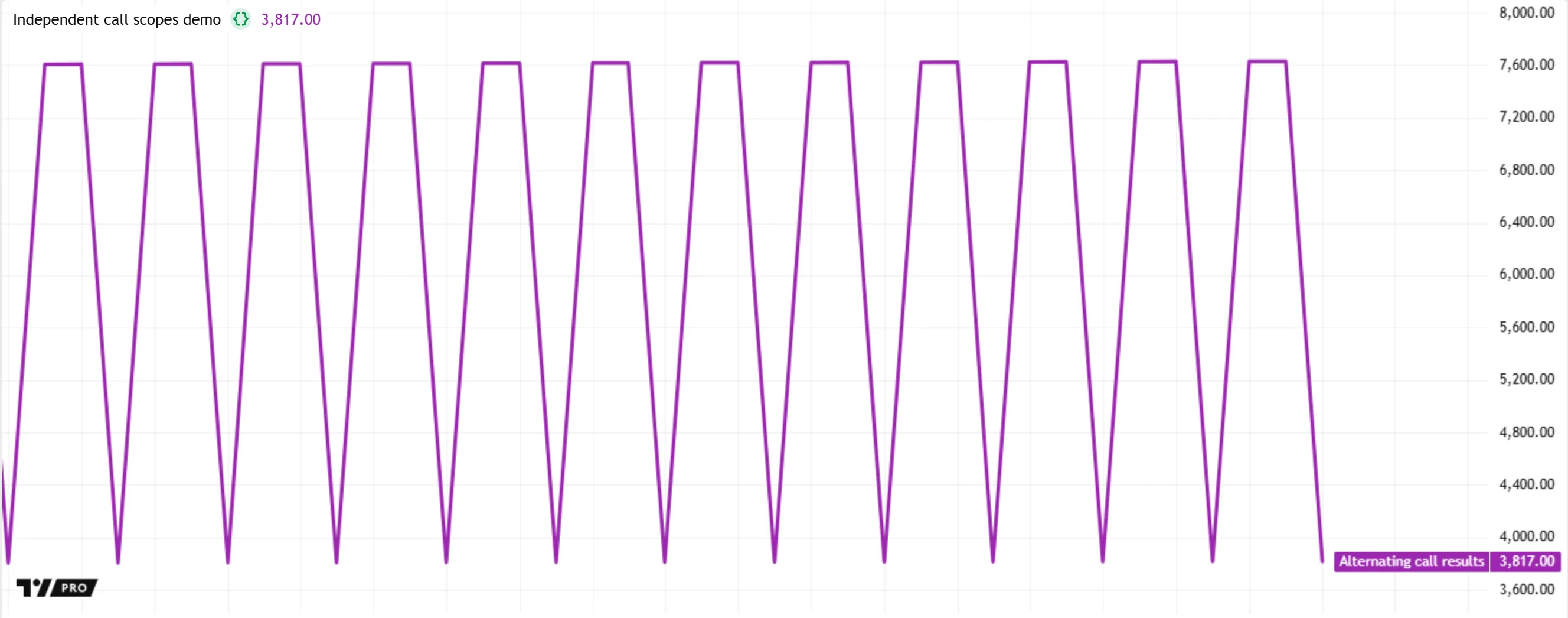
It is crucial to emphasize that each function call written in the source code has one unique scope created from the function’s definition. Repeated evaluations of the same written call do not create additional scopes with separate local variables and history. For example, a function call written in the body of a loop performs calculations using the same local series on every iteration; it does not calculate on different versions of those series for each separate iteration.
The following script demonstrates this behavior. The source code includes two written calls to our previous accumulate() function. The script evaluates the first call in the global scope, and the second inside the body of a for loop that performs 10 iterations per execution. It then plots the results of both calls in a separate pane:
A newcomer to Pine might expect the results of both accumulate() calls to be equal. However, the result of the call inside the loop is 10 times that of the call evaluated in the global scope. This difference occurs because the call written in the loop does not have separate scopes for each iteration; every evaluation of that call modifies the same version of the persistent total variable. Consequently, the value returned by the loop’s accumulate() call increases by 10 instead of one on each bar:
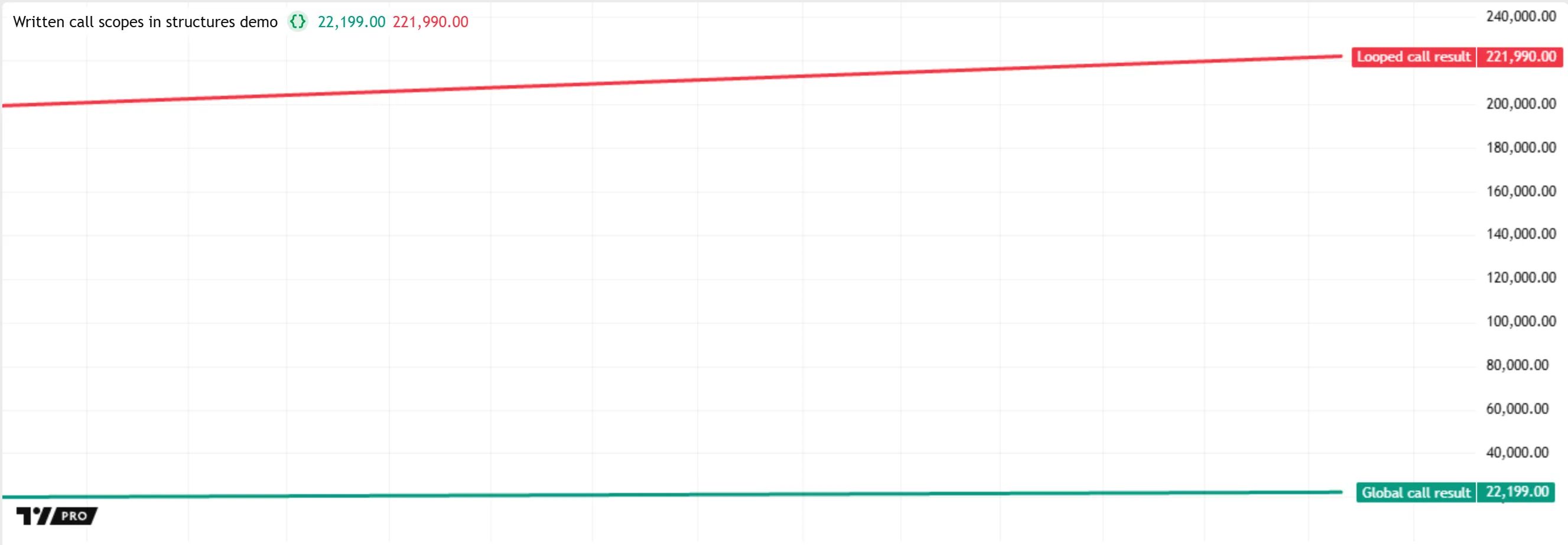
Note that:
- Both
accumulate()calls return the same result if we remove var from thetotalvariable declaration. Without the keyword, each call’s version of thetotalvariable no longer persists. Instead, every evaluation of the call re-declares the variable and initializes it to 0 before adding the value of thesourceargument.
Function overloading
Function overloads are unique versions of a function that share the same name but differ in their required parameter types. Overloading enables function calls using the same identifier to perform different tasks based on their specified arguments. Programmers often write overloads to group similar calculations for specific types under a single function name, offering a convenient alternative to defining several related functions with unique names.
In Pine Script, a function overload is valid only if its definition satisfies one of the following conditions:
- It has a different number of required parameters (parameters without default arguments) than that of any other defined overload.
- It has the same number of required parameters as another overload, but at least one required parameter has a different qualified type than the one declared at the same position in the other overload’s header.
The following code block defines three overloads of a custom negate() function. Each overload has a different parameter type and performs a distinct task. The first overload uses the - operator to negate a “float” or “int” value; the second uses the not operator to negate a “bool” value; and the third calculates the sRGB negative of a “color” value using the built-in color.*() functions:
Note that:
- The
valueparameter of eachnegate()overload automatically inherits the “series” qualifier, because its declaration includes a type keyword without a qualifier keyword, and the overload does not use the parameter in a local function call that requires a “simple” or weaker qualifier. - We included annotations to document each separate overload. As a user writes a
negate()call, the Pine Editor shows the documentation for one of the overloads in a pop-up window. While the window is open, the user can view the documentation for the other overloads by using the Up and Down arrow keys.
With our function overloads defined, we can use negate() calls for different type-specific tasks. The script below uses a call to each overload. First, it uses the second overload to calculate the opposite of the condition close > open. It then uses the negated condition to determine the value of a plotted series. The plotted value is the result of negate(close) if the condition is true, and the value of close otherwise. The script colors the plot using the negative of the chart’s background color (negate(chart.bg_color)):
It’s important to emphasize that a function overload is valid only if its signature contains a unique set of qualified types for its required parameters. Differences in optional parameters (the parameters that have default arguments) do not affect the validity of overloads. The compiler raises an error if two overloads share the same required parameter types and differ only in optional parameters, because it cannot determine which overload to use for all possible function calls.
For example, the following code block defines a fourth negate() overload with two “float” parameters. The overload’s first parameter requires an argument, but the second one does not because it has a default value. With this addition, any negate() call with a single “float” argument becomes ambiguous. Such a call might refer to the first overload or the fourth, and the compiler cannot confirm which one to use in that case. Therefore, the extra overload causes a compilation error:
Another crucial limitation to note is that the names of parameters do not affect the validity of overloads. The compiler validates overloads by analyzing only the qualified types of their required parameters at each position in the function headers, because function calls can use positional or named arguments for each parameter. Named arguments specify the parameter to which they apply. For example, f(x = 10) passes the value 10 to the x parameter of the f() call. In contrast, positional arguments omit names and apply to the parameters in order: the first argument to the first parameter, the second to the second parameter, and so on.
If two overloads have the same parameter types but different parameter names, a compilation error occurs, because any call that uses positional arguments is ambiguous. For example, the code block below defines a separate negate() overload with a single “float” parameter named comparedValue. That overload causes a compilation error, as the required parameter’s qualified type matches that of the value parameter in the first overload:
In Pine, function overloads can contain calls to overloads with the same function name in their bodies, but only if those overloads are defined first. However, just like non-overloaded functions, an overload cannot use calls to itself within its body.
For example, the script version below defines a fourth negate() overload with two required “float” parameters. The new overload calculates the product of its arguments, then calls the first overload of negate() to change the result’s sign. This script compiles successfully, because the fourth overload uses a separate negate() implementation in its scope, not a call to itself:
Note that:
- If we change the fourth overload to use a
negate()call with two “float” arguments, a compilation error occurs because the overload calls itself in that case. Even if Pine allowed recursive functions, using such an overload would cause an error because it creates the equivalent of an infinite loop, where a single call activates a second call, the second call activates a third one, and so on.
Limitations
This section explains several key limitations common to all user-defined functions. These same limitations also apply to user-defined methods.
No global-only built-in function calls
The body of a user-defined function can contain calls to most other functions or methods, or previously defined overloads with the same function name. However, a function cannot use calls to the following built-in functions inside its scope:
- Declaration statements: indicator(), strategy(), and library().
- Plot-related functions: plot(), hline(), fill(), plotshape(), plotchar(), plotarrow(), plotbar(), plotcandle(), barcolor(), bgcolor(), and alertcondition().
Global variables can be assigned values returned by functions in order to be used in calls to the above functions. However, the calls to these functions are allowed only in the script’s global scope, outside the operands of ternary operations or other conditional expressions.
Consistent types for each call
Each written call to a user-defined function must have consistent parameter types and return types during each evaluation of that call. The call cannot accept varying argument types throughout the script’s runtime, nor can it change its return type. Similar limitations also apply to other structures and expressions, including loops, conditional structures, and ternary operations.
Cannot modify global variables or parameters
The body of a user-defined function cannot use the reassignment or compound assignment operators to modify variables declared in the global scope. Likewise, it cannot use these operators to reassign function parameters. The value or reference assigned to a global variable or the parameter of a function call cannot change while the script evaluates the call. See the Function scopes section for an example.
No nested definitions
The body of a user-defined function cannot contain the definition of another user-defined function. Likewise, loops and conditional structures cannot include function definitions in their local blocks. Function and method definitions are allowed only in the script’s global scope.
For example, the following f() function definition causes a compilation error, because it attempts to define another function, g(), within its body:
Instead of attempting to define g() within the scope of f(), we can move the definition of g() above f() in the global scope:
No recursive functions
In contrast to functions in some programming languages, user-defined functions in Pine Script cannot contain calls to themselves within their bodies. Instead of using recursive function structures, programmers can replace those structures with equivalent loop calculations.
For instance, the following gcd() function causes a compilation error because it includes a gcd() call within its body:
Instead of attempting to use recursion, we can reformat the function’s structure to perform the necessary calculations using iteration. The example version below achieves our intended calculations using a while loop and no recursive gcd() calls: