Stochastic Ensembling of OutputsStochastic Ensembling of Outputs
🙏🏻 This is a simple tool/method that would solve naturally many well known problems:
“Price reversed 1 tick before the actual level, not executing my limit order”
“I consider intraday trend change by checking whether price is above/below VWAP, but is 1 tick enough? What to do, price is now whipsawing around vwap...”.
“I want to gradually accumulate a position around a chosen anchor. But where exactly should I put my orders? And I want to automate it ofc.“
“All these DSP adepts are telling you about some kind of noise in the markets… But how can I actually see it?”
The easy fix is to make things more analog less digital, by synthesizing numerous noise instances & adding it to any price-applied metric of yours. The ones who fw techno & psytrance, and other music, probably don’t need any more explanations. Then by checking not just 2 lines or 1 process against another one, you will be checking cloud vs cloud of lines, even allowing you to introduce proxies of probabilities. More crosses -> more confirmation to act.
How-to use:
The tool has 2 inputs: source and target:
Sources should always be the underlying process. If you apply the tool to price based metric, leave it hlcc4 unless you have a better one point estimate for each bar;
Target is your target, e.g if you want to apply it to VWAP, pick VWAP as target. You can thee on the chart above how trading activity recently never exactly touched VWAP, however noised instances of VWAP 'were' touched
The code is clean and written in modular form, you can simply copy paste it to any script of yours if you don't want to have multiple study-on-study script pairs.
^^ applied to prev days highs and lows
^^ applied to MBAD extensions and basis
^^ applied to input series itself
Here’s how it works, no ML, no “AI”, no 1k lines of code, just stats:
The problem with metrics, even if they are time aware like WMA, is that they still do not directly gain information about “changes” between datapoints. If we pick noise characteristics to match these changes, we’d effectively introduce this info into our ops.
^^ this screenshot represents 2 very different processes: a sine wave and white noise, see how the noise instances learned from each process differ significantly.
Changes can be represented as AR1 process . It’s dead simple, no PHD needed, it’s just how the current datapoint is related (or not) to the previous datapoint, no more than 1, and how this relationship holds/evolves over time. Unlike the mainstream approach like MLE, I estimate this relationship (phi parameter) via MoM but giving more weights to more recent datapoints via exponential smoothing over all the data available on your charts (so I encode temporal information), algocomplexity is O(1), lighting fast, just one pass. <- that gives phi , we’d use it as color for our noise generator
Then we just need to estimate noise amplitude ( gamma ) via checking what AR1 model actually thought vs the reality, variance of these innovations. Same via exponential smoothing, time aware, O(1), one pass, it’s all it does.
Then we generate white gaussian noise, and apply 2 estimated parameters (phi and gamma), and that’s all.
Omg, I think I just made my first real DSP script xd
Just like Monte Carlo for risk management, this is so simple and natural I can’t believe so many “pros” hide it and never talk about it in open access. Sharing it here on TradingView would’ve not done anything critical for em, but many would’ve benefited.
∞
MONTECARLO

Multi Brownian Forecast📊 Multi Brownian Forecast (Time-Adaptive, Probabilistic)
This indicator uses a sophisticated Geometric Brownian Motion (GBM) Monte Carlo simulation to project future price paths. It adapts to any chart timeframe and provides quantitative, multi-period probability signals.
---
🧠 Core Mathematical Methodology
The model relies on GBM, which is a continuous-time stochastic process that models asset prices.
1. Historical Analysis (Drift & Volatility):
* The script first calculates Logarithmic Returns over a user-defined Historical Lookback (Hours) .
* Drift ($\mu$): Computed as the average of the log returns.
* Volatility ($\sigma$): Computed as the standard deviation of the log returns.
* These values are then time-adapted to an hourly step, compensating for the chart's current timeframe (e.g., 5-minute, 1-hour).
2. Monte Carlo Simulation:
* It runs a specified Number of Simulations (e.g., 1000).
* For each simulation, the price is stepped forward hourly using the GBM formula, which incorporates the calculated drift and a random shock drawn from a normal distribution (generated via the Box-Muller transform ).
---
✨ Key Features
Probabilistic Quartile Forecast: Plots a dynamic "cone" of probability on the chart. It shows key price percentiles (Q1, Q2/Median, Q3, and Q4/Outer Bound) at the forecast's expiration, visualizing the expected range of price outcomes based on the simulations.
Multi-Period Probability Signals: This is the core signal feature. Users can define multiple, independent forecast periods (e.g., 4h, 16h, 48h) in a comma-separated list.
* For each period, a Probability Up and Probability Down is calculated based on hitting a custom Target Price Change (%) (e.g., 2%) at a certain confidence level given a simulation over the historical backlook.
* The probabilities are displayed in a chart table. The cell text turns white if the calculated probability exceeds the user-defined Signal Confidence (%) .
Conditional Fibonacci Retracement: Optionally displays a Fibonacci Retracement on the chart. This feature is only activated when one of the multi-period signals reaches its minimum confidence threshold, providing a contextual technical level when a probabilistic edge is found.

Brownian Motion Probabilistic Forecasting (Time Adaptive)Probabilistic Price Forecast Indicator
Overview
The Probabilistic Price Forecast is an advanced technical analysis tool designed for the TradingView platform. Instead of predicting a single future price, this indicator uses a Monte Carlo simulation to model thousands of potential future price paths, generating a cone of possibilities and calculating the probability of specific outcomes.
This allows traders to move beyond simple price targets and ask more sophisticated questions, such as: "What is the probability that this stock will increase by 5% over the next 24 hours?"
Core Concept: Geometric Brownian Motion
The indicator's forecasting model is built on the principles of Geometric Brownian Motion (GBM) , a widely accepted mathematical model for describing the random movements of financial asset prices. The core idea is that the next price step is a function of the asset's historical trend (drift), its volatility, and a random "shock."
The formula used to project each price step in the simulation is:
next_price = current_price * exp( (μ - (σ²/2))Δt + σZ√(Δt) )
Where:
μ (mu) represents the drift , which is the average historical return.
σ (sigma) represents the volatility , measured by the standard deviation of historical returns.
Z is a random variable from a standard normal distribution, representing the random "shock" or new information affecting the price.
Δt (delta t) is the time step for each projection.
How It Works
The indicator performs a comprehensive analysis on the most recent bar of the chart:
**Historical Analysis**: It first analyzes a user-defined historical period (e.g., the last 240 hours of price data) to calculate the asset's historical drift (μ) and volatility (σ) from its logarithmic returns.
**Monte Carlo Simulation**: It then runs thousands of simulations (e.g., 2000) of future price paths over a specified forecast period (e.g., the next 24 hours). Each path is unique due to the random shock (Z) applied at every step.
**Probability Distribution**: After all simulations are complete, it collects the final price of each path and sorts them to build a probability distribution of potential outcomes.
**Visualization and Signaling**: Finally, it visualizes this distribution on the chart and generates signals based on the user's criteria.
Key Features & Configuration
The indicator is highly configurable, allowing you to tailor its analysis to your specific needs.
Time-Adaptive Periods
The lookback and forecast periods are defined in hours , not bars. The script automatically converts these hour-based inputs into the correct number of bars based on the chart's current timeframe, ensuring the analysis remains consistent across different chart resolutions.
Forecast Quartiles
You can visualize the forecast as a "cone of probability" on the chart. The indicator draws lines and a shaded area representing the price levels for different quartiles (percentiles) of the simulation results. By default, this shows the range between the 25th and 95th percentiles.
Independent Bullish and Bearish Signals
The indicator allows you to set independent criteria for bullish and bearish signals, providing greater flexibility. You can configure:
A bullish signal for an X% confidence of a Y% price increase.
A bearish signal for a W% confidence of a Z% price decrease.
For example, you can set it to alert you for a 90% chance of a 2% drop, while simultaneously looking for a 60% chance of a 10% rally.
How to Interpret the Indicator
The Forecast Cone : The blue shaded area on the chart represents the probable range of future prices. The width of the cone indicates the expected volatility; a wider cone means higher uncertainty. The price labels on the right side of the cone show the calculated percentile levels at the end of the forecast period.
Green Signal Label : A green "UP signal" label appears when the probability of the price increasing by your target percentage exceeds your defined confidence level.
Red Signal Label : A red "DOWN signal" label appears when the probability of the price decreasing by your target percentage exceeds your confidence level.
This tool provides a statistical edge for understanding future possibilities but should be used in conjunction with other analysis techniques.

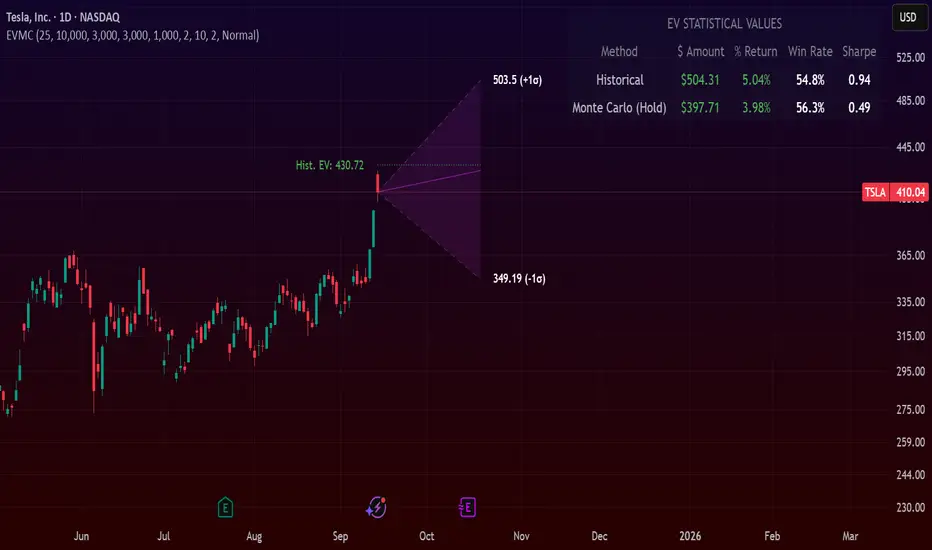
Expected Value Monte CarloI created this indicator after noticing that there was no Expected Value indicator here on TradingView.
The EVMC provides statistical Expected Value to what might happen in the future regarding the asset you are analyzing.
It uses 2 quantitative methods:
Historical Backtest to ground your analysis in long-term, factual data.
Monte Carlo Simulation to project a cone of probable future outcomes based on recent market behavior.
This gives you a data-driven edge to quantify risk, and make more informed trading decisions.
The indicator includes:
Dual analysis: Combines historical probability with forward-looking simulation.
Quantified projections: Provides the Expected Value ($ and %), Win Rate, and Sharpe Ratio for both methods.
Asset-aware: Automatically adjusts its calculations for Stocks (252 trading days) and Crypto (365 days) for mathematical accuracy.
The projection cone shows the mean expected path and the +/- 1 standard deviation range of outcomes.
No repainting
Calculation:
1. Historical Expected Value:
This is a systematic backtest over thousands of bars. It calculates the return Rᵢ for N past trades (buy-and-hold). The Historical EV is the simple average of these returns, giving a baseline performance measure.
Historical EV % = (Σ Rᵢ) / N
2. Monte Carlo Projection:
This projection uses the Geometric Brownian Motion (GBM) model to simulate thousands of future price paths based on the market's recent behavior.
It first measures the drift (μ), or recent trend, and volatility (σ), or recent risk, from the Projection Lookback period. It then projects a final return for each simulation using the core GBM formula:
Projected Return = exp( (μ - σ²/2)T + σ√T * Z ) - 1
(Where T is the time horizon and Z is a random variable for the simulation.)
The purple line on the chart is the average of all simulated outcomes (the Monte Carlo EV). The cone represents one standard deviation of those outcomes.
The dashed lines represent one standard deviation (+/- 1σ) from the average, forming a cone of probable outcomes. Roughly 68% of the simulated paths ended within this cone.
This projection answers the question: "If the recent trend and volatility continue, where is the price most likely to go?"
Here's how to read the indicator
Expected Value ($/%): Is my average trade profitable?
Win Rate: How often can I expect to be right?
Sharpe Ratio: Am I being adequately compensated for the risk I'm taking?
User Guide
Max trade duration (bars): This is your analysis timeframe. Are you interested in the probable outcome over the next month (21 bars), quarter (63 bars), or year (252 bars)?
Position size ($): Set this to your typical trade size to see the Expected Value in real dollar terms.
Projection lookback (bars): This is the most important input for the Monte Carlo model. A short lookback (e.g., 50) makes the projection highly sensitive to recent momentum. Use this to identify potential recency bias. A long lookback (e.g., 252) provides a more stable, long-term projection of trend and volatility.
Historical Lookback (bars): For the historical backtest, more data is always better. Use the maximum that your TradingView plan allows for the most statistically significant results.
Use TP/SL for Historical EV: Check this box to see how the historical performance would have changed if you had used a simple Take Profit and Stop Loss, rather than just holding for the full duration.
I hope you find this indicator useful and please let me know if you have any suggestions. 😊
Martingale Strategy Simulator [BackQuant]Martingale Strategy Simulator
Purpose
This indicator lets you study how a martingale-style position sizing rule interacts with a simple long or short trading signal. It computes an equity curve from bar-to-bar returns, adapts position size after losing streaks, caps exposure at a user limit, and summarizes risk with portfolio metrics. An optional Monte Carlo module projects possible future equity paths from your realized daily returns.
What a martingale is
A martingale sizing rule increases stake after losses and resets after a win. In its classical form from gambling, you double the bet after each loss so that a single win recovers all prior losses plus one unit of profit. In markets there is no fixed “even-money” payout and returns are multiplicative, so an exact recovery guarantee does not exist. The core idea is unchanged:
Lose one leg → increase next position size
Lose again → increase again
Win → reset to the base size
The expectation of your strategy still depends on the signal’s edge. Sizing does not create positive expectancy on its own. A martingale raises variance and tail risk by concentrating more capital as a losing streak develops.
What it plots
Equity – simulated portfolio equity including compounding
Buy & Hold – equity from holding the chart symbol for context
Optional helpers – last trade outcome, current streak length, current allocation fraction
Optional diagnostics – daily portfolio return, rolling drawdown, metrics table
Optional Monte Carlo probability cone – p5, p16, p50, p84, p95 aggregate bands
Model assumptions
Bar-close execution with no slippage or commissions
Shorting allowed and frictionless
No margin interest, borrow fees, or position limits
No intrabar moves or gaps within a bar (returns are close-to-close)
Sizing applies to equity fraction only and is capped by your setting
All results are hypothetical and for education only.
How the simulator applies it
1) Directional signal
You pick a simple directional rule that produces +1 for long or −1 for short each bar. Options include 100 HMA slope, RSI above or below 50, EMA or SMA crosses, CCI and other oscillators, ATR move, BB basis, and more. The stance is evaluated bar by bar. When the stance flips, the current trade ends and the next one starts.
2) Sizing after losses and wins
Position size is a fraction of equity:
Initial allocation – the starting fraction, for example 0.15 means 15 percent of equity
Increase after loss – multiply the next allocation by your factor after a losing leg, for example 2.00 to double
Reset after win – return to the initial allocation
Max allocation cap – hard ceiling to prevent runaway growth
At a high level the size after k consecutive losses is
alloc(k) = min( cap , base × factor^k ) .
In practice the simulator changes size only when a leg ends and its PnL is known.
3) Equity update
Let r_t = close_t / close_{t-1} − 1 be the symbol’s bar return, d_{t−1} ∈ {+1, −1} the prior bar stance, and a_{t−1} the prior bar allocation fraction. The simulator compounds:
eq_t = eq_{t−1} × (1 + a_{t−1} × d_{t−1} × r_t) .
This is bar-based and avoids intrabar lookahead. Costs, slippage, and borrowing costs are not modeled.
Why traders experiment with martingale sizing
Mean-reversion contexts – if the signal often snaps back after a string of losses, adding size near the tail of a move can pull the average entry closer to the turn
Behavioral or microstructure edges – some rules have modest edge but frequent small whipsaws; size escalation may shorten time-to-recovery when the edge manifests
Exploration and stress testing – studying the relationship between streaks, caps, and drawdowns is instructive even if you do not deploy martingale sizing live
Why martingale is dangerous
Martingale concentrates capital when the strategy is performing worst. The main risks are structural, not cosmetic:
Loss streaks are inevitable – even with a 55 percent win rate you should expect multi-loss runs. The probability of at least one k-loss streak in N trades rises quickly with N.
Size explodes geometrically – with factor 2.0 and base 10 percent, the sequence is 10, 20, 40, 80, 100 (capped) after five losses. Without a strict cap, required size becomes infeasible.
No fixed payout – in gambling, one win at even odds resets PnL. In markets, there is no guaranteed bounce nor fixed profit multiple. Trends can extend and gaps can skip levels.
Correlation of losses – losses cluster in trends and in volatility bursts. A martingale tends to be largest just when volatility is highest.
Margin and liquidity constraints – leverage limits, margin calls, position limits, and widening spreads can force liquidation before a mean reversion occurs.
Fat tails and regime shifts – assumptions of independent, Gaussian returns can understate tail risk. Structural breaks can keep the signal wrong for much longer than expected.
The simulator exposes these dynamics in the equity curve, Max Drawdown, VaR and CVaR, and via Monte Carlo sketches of forward uncertainty.
Interpreting losing streaks with numbers
A rough intuition: if your per-trade win probability is p and loss probability is q=1−p , the chance of a specific run of k consecutive losses is q^k . Over many trades, the chance that at least one k-loss run occurs grows with the number of opportunities. As a sanity check:
If p=0.55 , then q=0.45 . A 6-loss run has probability q^6 ≈ 0.008 on any six-trade window. Across hundreds of trades, a 6 to 8-loss run is not rare.
If your size factor is 1.5 and your base is 10 percent, after 8 losses the requested size is 10% × 1.5^8 ≈ 25.6% . With factor 2.0 it would try to be 10% × 2^8 = 256% but your cap will stop it. The equity curve will still wear the compounded drawdown from the sequence that led to the cap.
This is why the cap setting is central. It does not remove tail risk, but it prevents the sizing rule from demanding impossible positions
Note: The p and q math is illustrative. In live data the win rate and distribution can drift over time, so real streaks can be longer or shorter than the simple q^k intuition suggests..
Using the simulator productively
Parameter studies
Start with conservative settings. Increase one element at a time and watch how the equity, Max Drawdown, and CVaR respond.
Initial allocation – lower base reduces volatility and drawdowns across the board
Increase factor – set modestly above 1.0 if you want the effect at all; doubling is aggressive
Max cap – the most important brake; many users keep it between 20 and 50 percent
Signal selection
Keep sizing fixed and rotate signals to see how streak patterns differ. Trend-following signals tend to produce long wrong-way streaks in choppy ranges. Mean-reversion signals do the opposite. Martingale sizing interacts very differently with each.
Diagnostics to watch
Use the built-in metrics to quantify risk:
Max Drawdown – worst peak-to-trough equity loss
Sharpe and Sortino – volatility and downside-adjusted return
VaR 95 percent and CVaR – tail risk measures from the realized distribution
Alpha and Beta – relationship to your chosen benchmark
If you would like to check out the original performance metrics script with multiple assets with a better explanation on all metrics please see
Monte Carlo exploration
When enabled, the forecast draws many synthetic paths from your realized daily returns:
Choose a horizon and a number of runs
Review the bands: p5 to p95 for a wide risk envelope; p16 to p84 for a narrower range; p50 as the median path
Use the table to read the expected return over the horizon and the tail outcomes
Remember it is a sketch based on your recent distribution, not a predictor
Concrete examples
Example A: Modest martingale
Base 10 percent, factor 1.25, cap 40 percent, RSI>50 signal. You will see small escalations on 2 to 4 loss runs and frequent resets. The equity curve usually remains smooth unless the signal enters a prolonged wrong-way regime. Max DD may rise moderately versus fixed sizing.
Example B: Aggressive martingale
Base 15 percent, factor 2.0, cap 60 percent, EMA cross signal. The curve can look stellar during favorable regimes, then a single extended streak pushes allocation to the cap, and a few more losses drive deep drawdown. CVaR and Max DD jump sharply. This is a textbook case of high tail risk.
Strengths
Bar-by-bar, transparent computation of equity from stance and size
Explicit handling of wins, losses, streaks, and caps
Portable signal inputs so you can A–B test ideas quickly
Risk diagnostics and forward uncertainty visualization in one place
Example, Rolling Max Drawdown
Limitations and important notes
Martingale sizing can escalate drawdowns rapidly. The cap limits position size but not the possibility of extended adverse runs.
No commissions, slippage, margin interest, borrow costs, or liquidity limits are modeled.
Signals are evaluated on closes. Real execution and fills will differ.
Monte Carlo assumes independent draws from your recent return distribution. Markets often have serial correlation, fat tails, and regime changes.
All results are hypothetical. Use this as an educational tool, not a production risk engine.
Practical tips
Prefer gentle factors such as 1.1 to 1.3. Doubling is usually excessive outside of toy examples.
Keep a strict cap. Many users cap between 20 and 40 percent of equity per leg.
Stress test with different start dates and subperiods. Long flat or trending regimes are where martingale weaknesses appear.
Compare to an anti-martingale (increase after wins, cut after losses) to understand the other side of the trade-off.
If you deploy sizing live, add external guardrails such as a daily loss cut, volatility filters, and a global max drawdown stop.
Settings recap
Backtest start date and initial capital
Initial allocation, increase-after-loss factor, max allocation cap
Signal source selector
Trading days per year and risk-free rate
Benchmark symbol for Alpha and Beta
UI toggles for equity, buy and hold, labels, metrics, PnL, and drawdown
Monte Carlo controls for enable, runs, horizon, and result table
Final thoughts
A martingale is not a free lunch. It is a way to tilt capital allocation toward losing streaks. If the signal has a real edge and mean reversion is common, careful and capped escalation can reduce time-to-recovery. If the signal lacks edge or regimes shift, the same rule can magnify losses at the worst possible moment. This simulator makes those trade-offs visible so you can calibrate parameters, understand tail risk, and decide whether the approach belongs anywhere in your research workflow.

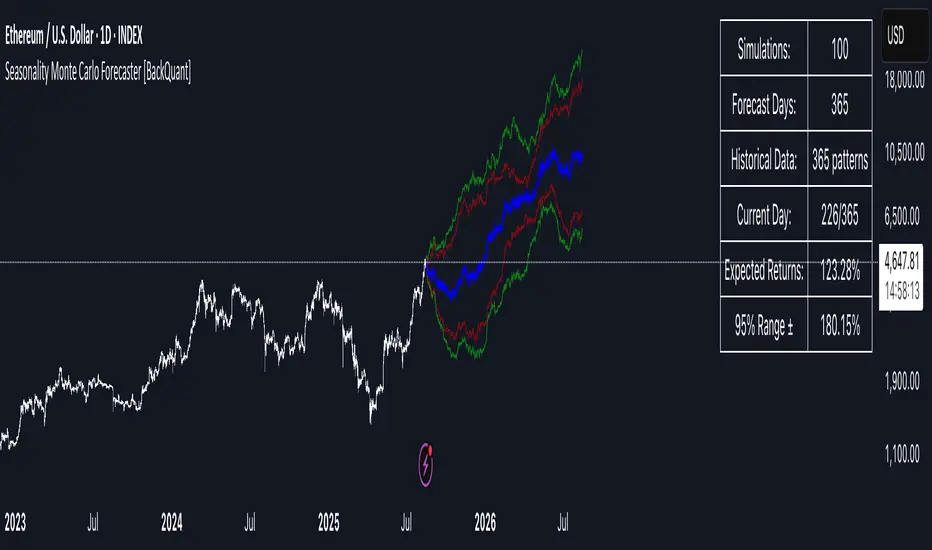
Seasonality Monte Carlo Forecaster [BackQuant]Seasonality Monte Carlo Forecaster
Plain-English overview
This tool projects a cone of plausible future prices by combining two ideas that traders already use intuitively: seasonality and uncertainty. It watches how your market typically behaves around this calendar date, turns that seasonal tendency into a small daily “drift,” then runs many randomized price paths forward to estimate where price could land tomorrow, next week, or a month from now. The result is a probability cone with a clear expected path, plus optional overlays that show how past years tended to move from this point on the calendar. It is a planning tool, not a crystal ball: the goal is to quantify ranges and odds so you can size, place stops, set targets, and time entries with more realism.
What Monte Carlo is and why quants rely on it
• Definition . Monte Carlo simulation is a way to answer “what might happen next?” when there is randomness in the system. Instead of producing a single forecast, it generates thousands of alternate futures by repeatedly sampling random shocks and adding them to a model of how prices evolve.
• Why it is used . Markets are noisy. A single point forecast hides risk. Monte Carlo gives a distribution of outcomes so you can reason in probabilities: the median path, the 68% band, the 95% band, tail risks, and the chance of hitting a specific level within a horizon.
• Core strengths in quant finance .
– Path-dependent questions : “What is the probability we touch a stop before a target?” “What is the expected drawdown on the way to my objective?”
– Pricing and risk : Useful for path-dependent options, Value-at-Risk (VaR), expected shortfall (CVaR), stress paths, and scenario analysis when closed-form formulas are unrealistic.
– Planning under uncertainty : Portfolio construction and rebalancing rules can be tested against a cloud of plausible futures rather than a single guess.
• Why it fits trading workflows . It turns gut feel like “seasonality is supportive here” into quantitative ranges: “median path suggests +X% with a 68% band of ±Y%; stop at Z has only ~16% odds of being tagged in N days.”
How this indicator builds its probability cone
1) Seasonal pattern discovery
The script builds two day-of-year maps as new data arrives:
• A return map where each calendar day stores an exponentially smoothed average of that day’s log return (yesterday→today). The smoothing (90% old, 10% new) behaves like an EWMA, letting older seasons matter while adapting to new information.
• A volatility map that tracks the typical absolute return for the same calendar day.
It calculates the day-of-year carefully (with leap-year adjustment) and indexes into a 365-slot seasonal array so “March 18” is compared with past March 18ths. This becomes the seasonal bias that gently nudges simulations up or down on each forecast day.
2) Choice of randomness engine
You can pick how the future shocks are generated:
• Daily mode uses a Gaussian draw with the seasonal bias as the mean and a volatility that comes from realized returns, scaled down to avoid over-fitting. It relies on the Box–Muller transform internally to turn two uniform random numbers into one normal shock.
• Weekly mode uses bootstrap sampling from the seasonal return history (resampling actual historical daily drifts and then blending in a fraction of the seasonal bias). Bootstrapping is robust when the empirical distribution has asymmetry or fatter tails than a normal distribution.
Both modes seed their random draws deterministically per path and day, which makes plots reproducible bar-to-bar and avoids flickering bands.
3) Volatility scaling to current conditions
Markets do not always live in average volatility. The engine computes a simple volatility factor from ATR(20)/price and scales the simulated shocks up or down within sensible bounds (clamped between 0.5× and 2.0×). When the current regime is quiet, the cone narrows; when ranges expand, the cone widens. This prevents the classic mistake of projecting calm markets into a storm or vice versa.
4) Many futures, summarized by percentiles
The model generates a matrix of price paths (capped at 100 runs for performance inside TradingView), each path stepping forward for your selected horizon. For each forecast day it sorts the simulated prices and pulls key percentiles:
• 5th and 95th → approximate 95% band (outer cone).
• 16th and 84th → approximate 68% band (inner cone).
• 50th → the median or “expected path.”
These are drawn as polylines so you can immediately see central tendency and dispersion.
5) A historical overlay (optional)
Turn on the overlay to sketch a dotted path of what a purely seasonal projection would look like for the next ~30 days using only the return map, no randomness. This is not a forecast; it is a visual reminder of the seasonal drift you are biasing toward.
Inputs you control and how to think about them
Monte Carlo Simulation
• Price Series for Calculation . The source series, typically close.
• Enable Probability Forecasts . Master switch for simulation and drawing.
• Simulation Iterations . Requested number of paths to run. Internally capped at 100 to protect performance, which is generally enough to estimate the percentiles for a trading chart. If you need ultra-smooth bands, shorten the horizon.
• Forecast Days Ahead . The length of the cone. Longer horizons dilute seasonal signal and widen uncertainty.
• Probability Bands . Draw all bands, just 95%, just 68%, or a custom level (display logic remains 68/95 internally; the custom number is for labeling and color choice).
• Pattern Resolution . Daily leans on day-of-year effects like “turn-of-month” or holiday patterns. Weekly biases toward day-of-week tendencies and bootstraps from history.
• Volatility Scaling . On by default so the cone respects today’s range context.
Plotting & UI
• Probability Cone . Plots the outer and inner percentile envelopes.
• Expected Path . Plots the median line through the cone.
• Historical Overlay . Dotted seasonal-only projection for context.
• Band Transparency/Colors . Customize primary (outer) and secondary (inner) band colors and the mean path color. Use higher transparency for cleaner charts.
What appears on your chart
• A cone starting at the most recent bar, fanning outward. The outer lines are the ~95% band; the inner lines are the ~68% band.
• A median path (default blue) running through the center of the cone.
• An info panel on the final historical bar that summarizes simulation count, forecast days, number of seasonal patterns learned, the current day-of-year, expected percentage return to the median, and the approximate 95% half-range in percent.
• Optional historical seasonal path drawn as dotted segments for the next 30 bars.
How to use it in trading
1) Position sizing and stop logic
The cone translates “volatility plus seasonality” into distances.
• Put stops outside the inner band if you want only ~16% odds of a stop-out due to noise before your thesis can play.
• Size positions so that a test of the inner band is survivable and a test of the outer band is rare but acceptable.
• If your target sits inside the 68% band at your horizon, the payoff is likely modest; outside the 68% but inside the 95% can justify “one-good-push” trades; beyond the 95% band is a low-probability flyer—consider scaling plans or optionality.
2) Entry timing with seasonal bias
When the median path slopes up from this calendar date and the cone is relatively narrow, a pullback toward the lower inner band can be a high-quality entry with a tight invalidation. If the median slopes down, fade rallies toward the upper band or step aside if it clashes with your system.
3) Target selection
Project your time horizon to N bars ahead, then pick targets around the median or the opposite inner band depending on your style. You can also anchor dynamic take-profits to the moving median as new bars arrive.
4) Scenario planning & “what-ifs”
Before events, glance at the cone: if the 95% band already spans a huge range, trade smaller, expect whips, and avoid placing stops at obvious band edges. If the cone is unusually tight, consider breakout tactics and be ready to add if volatility expands beyond the inner band with follow-through.
5) Options and vol tactics
• When the cone is tight : Prefer long gamma structures (debit spreads) only if you expect a regime shift; otherwise premium selling may dominate.
• When the cone is wide : Debit structures benefit from range; credit spreads need wider wings or smaller size. Align with your separate IV metrics.
Reading the probability cone like a pro
• Cone slope = seasonal drift. Upward slope means the calendar has historically favored positive drift from this date, downward slope the opposite.
• Cone width = regime volatility. A widening fan tells you that uncertainty grows fast; a narrow cone says the market typically stays contained.
• Mean vs. price gap . If spot trades well above the median path and the upper band, mean-reversion risk is high. If spot presses the lower inner band in an up-sloping cone, you are in the “buy fear” zone.
• Touches and pierces . Touching the inner band is common noise; piercing it with momentum signals potential regime change; the outer band should be rare and often brings snap-backs unless there is a structural catalyst.
Methodological notes (what the code actually does)
• Log returns are used for additivity and better statistical behavior: sim_ret is applied via exp(sim_ret) to evolve price.
• Seasonal arrays are updated online with EWMA (90/10) so the model keeps learning as each bar arrives.
• Leap years are handled; indexing still normalizes into a 365-slot map so the seasonal pattern remains stable.
• Gaussian engine (Daily mode) centers shocks on the seasonal bias with a conservative standard deviation.
• Bootstrap engine (Weekly mode) resamples from observed seasonal returns and adds a fraction of the bias, which captures skew and fat tails better.
• Volatility adjustment multiplies each daily shock by a factor derived from ATR(20)/price, clamped between 0.5 and 2.0 to avoid extreme cones.
• Performance guardrails : simulations are capped at 100 paths; the probability cone uses polylines (no heavy fills) and only draws on the last confirmed bar to keep charts responsive.
• Prerequisite data : at least ~30 seasonal entries are required before the model will draw a cone; otherwise it waits for more history.
Strengths and limitations
• Strengths :
– Probabilistic thinking replaces single-point guessing.
– Seasonality adds a small but meaningful directional bias that many markets exhibit.
– Volatility scaling adapts to the current regime so the cone stays realistic.
• Limitations :
– Seasonality can break around structural changes, policy shifts, or one-off events.
– The number of paths is performance-limited; percentile estimates are good for trading, not for academic precision.
– The model assumes tomorrow’s randomness resembles recent randomness; if regime shifts violently, the cone will lag until the EWMA adapts.
– Holidays and missing sessions can thin the seasonal sample for some assets; be cautious with very short histories.
Tuning guide
• Horizon : 10–20 bars for tactical trades; 30+ for swing planning when you care more about broad ranges than precise targets.
• Iterations : The default 100 is enough for stable 5/16/50/84/95 percentiles. If you crave smoother lines, shorten the horizon or run on higher timeframes.
• Daily vs. Weekly : Daily for equities and crypto where month-end and turn-of-month effects matter; Weekly for futures and FX where day-of-week behavior is strong.
• Volatility scaling : Keep it on. Turn off only when you intentionally want a “pure seasonality” cone unaffected by current turbulence.
Workflow examples
• Swing continuation : Cone slopes up, price pulls into the lower inner band, your system fires. Enter near the band, stop just outside the outer line for the next 3–5 bars, target near the median or the opposite inner band.
• Fade extremes : Cone is flat or down, price gaps to the upper outer band on news, then stalls. Favor mean-reversion toward the median, size small if volatility scaling is elevated.
• Event play : Before CPI or earnings on a proxy index, check cone width. If the inner band is already wide, cut size or prefer options structures that benefit from range.
Good habits
• Pair the cone with your entry engine (breakout, pullback, order flow). Let Monte Carlo do range math; let your system do signal quality.
• Do not anchor blindly to the median; recalc after each bar. When the cone’s slope flips or width jumps, the plan should adapt.
• Validate seasonality for your symbol and timeframe; not every market has strong calendar effects.
Summary
The Seasonality Monte Carlo Forecaster wraps institutional risk planning into a single overlay: a data-driven seasonal drift, realistic volatility scaling, and a probabilistic cone that answers “where could we be, with what odds?” within your trading horizon. Use it to place stops where randomness is less likely to take you out, to set targets aligned with realistic travel, and to size positions with confidence born from distributions rather than hunches. It will not predict the future, but it will keep your decisions anchored to probabilities—the language markets actually speak.
Monte Carlo (Polyline Traceback) [Kioseff Trading]Hello!
This script "Monte Carlo (Polyline Traceback) " performs a Monte Carlo simulation using polylines!
By using polylines, and tracing back the initial simulation to its origin point, we can better replicate the ideal output of a Monte Carlo simulation!
Such as:
The image above shows the output of a simulation (image sourced outside TV).
With this script, and polyline capabilities, we can come quite close on TradingView.
The image above shows the indicator in action! Not bad considering the ideal output.
Of course, the script is quite heavy and tries its best to circumvent limitations :D
You might run into load time errors, in which case you might try applying the built-in setting "Force Script Load". This setting will cut-off the visuals for some simulations, but has a higher chance of passing load-time limitations!
As shown in the image above, you can select to only show worst-case and best-case simulations. Using this option will reduce chart lag and improve load times.
Features
Monte Carlo Simulation: Performs Monte Carlo simulation to generate multiple future paths.
Asset Price: Can simulate future asset prices based on historical log returns.
Statistical Methods: Offers two simulation methods—Gaussian (Normal) distribution and Bootstrapping.
Adjustable Parameters: Offers numerous user-adjustable settings like number of simulations, forecast length, and more.
Historical Data Points: Option to specify the amount of historical data to be used in the simulation (price).
Best/Worst Case: Allows you to show only the best case / worst case outcome (range) for all simulations!
Thank you!

Anchored Monte Carlo Shuffled Projection [LuxAlgo]The Anchored Monte Carlo Shuffled Projection tool randomly simulates future price points based on historical bar movements made before a user-anchored point in time.
By anchoring our data and projections to a single point in time, users can better understand and reflect on how the price played out while taking into consideration our random simulations.
🔶 USAGE
After selecting the indicator to apply to the chart, you will be prompted to "Set the Anchor Point". Do so by clicking on the desired location on your chart, only time is used as the anchor point.
Note: To select a new anchor point when applied to the chart, click on the 'More' dropdown next to the indicator status bar (○○○), then select "Reset points...".
Alternate Method: You are also able to click and drag the vertical line that displays on the anchor point bar when the indicator is highlighted.
By randomly simulating bar movements, a range is developed of potential price action which could be utilized to locate future price development as well as potential support/resistance levels.
Performing numerous simulations and taking the average at each step will converge toward the result highlighted by the "Average Line", and can point out where the price might develop, assuming the trend and amount of volatility persist.
Current closing price + Sum of changes in the calculation window
This constraint will cause the simulations always to display an endpoint consistent with the current lookback's slope.
While this may be helpful to some traders, this indicator includes an option to produce a less biased range, as seen below:
🔶 DETAILS
The Anchored Monte Carlo Shuffled Projection tool creates simulations based on prices within a user-set lookback window originating at the specified anchor point. Simulations are done as follows:
Collect each bar's price changes in the user-set window.
Randomize the order of each change in the window.
Project the cumulative sum of the shuffled changes from the current closing price.
Collect data on each point along the way.
This is the process for the Default calculation; for the 'Randomize Direction' calculation, when added onto the front for every other change, the value is inverted, creating the randomized endpoints for each simulation.
The script contains each simulation's data for that bar, with a maximum of 1000 simulations.
To get a glimpse behind the scenes, each simulation (up to 99) can be viewed using the 'Visualize Simulations' Options, as seen below.
Because the script holds the full simulation data, the script can also calculate this data, such as standard deviations.
In this script the Standard deviation lines are the average of all standard deviations across the vertical data groups, this provides a singular value that can be displayed a distance away from the simulation center line.
🔶 SETTINGS
Lookback: Sets the number of Bars to include in calculations.
Simulation Count: Sets the number of randomized simulations to calculate. (Max 1000)
Randomize Direction: See Details Above. Creates a more 'Normalized' Distribution
Visualize Simulations: See Details Above. Turns on Visualizations, and colors are randomly generated. Visualized max does not cap the calculated max. If 1000 simulations are used, the data will be from 1000 simulations, however, only the last 99 simulations will be visualized.
🔹 Standard Deviations
Standard Deviation Multiplier: Sets the multiplier to use for the Standard Deviation distance away from the center line.
🔹 Style
Extend Lines: Extends the Simulated Value Lines into the future for further reference and analysis.

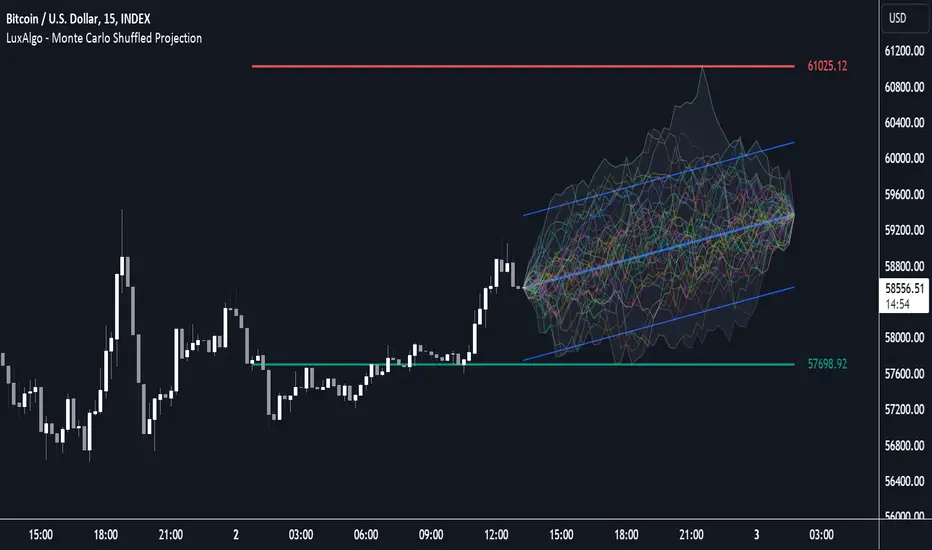
Monte Carlo Shuffled Projection [LuxAlgo]The Monte Carlo Shuffled Projection tool randomly simulates future price points based on historical bar movements made within a user-selected window.
The tool shows potential paths price might take in the future, as well as highlighting potential support/resistance levels.
Note that simulations and their resulting elements are subject to slight changes over time.
🔶 USAGE
By randomly simulating bar movements, a range is developed of potential price action which could be utilized to locate future price development as well as potential support/resistance levels.
Performing a large number of simulations and taking the average at each step will converge toward the result highlighted by the "Average Line", and can point out where the price might develop assuming the trend and amount of volatility persist.
Current closing price + Sum of changes in the calculation window)
This constraint will cause the simulations to always display an endpoint consistent with the current lookback's slope.
While this may be helpful to some traders, this indicator includes an option to produce a less biased range as seen below:
🔶 DETAILS
The Monte Carlo Shuffled Projection tool creates simulations based on the most recent prices within a user-set window. Simulations are done as follows:
Collect each bar's price changes in the user-set window.
Randomize the order of each change in the window.
Project the cumulative sum of the shuffled changes from the current closing price.
Collect data on each point along the way.
This is the process for the Default calculation, for the 'Randomize Direction' calculation, when added onto the front for every other change, the value is inverted, creating the randomized endpoints for each simulation.
The script contains each simulation's data for that bar with a maximum of 1000 simulations.
To get a glimpse behind the scenes each simulation (up to 99) can be viewed using the 'Visualize Simulations' Options as seen below.
Because the script holds the full simulation data, the script can also do calculations on this data, such as calculating standard deviations.
In this script the Standard deviation lines are the average of all standard deviations across the vertical data groups, this provides a singular value that can be displayed a distance away from the simulation center line.
🔶 SETTINGS
Color and Toggle Options are Provided throughout.
Lookback: Sets the number of Bars to include in calculations.
Simulation Count: Sets the number of randomized simulations to calculate. (Max 1000)
Randomize Direction: See Details Above. Creates a more 'Normalized' Distribution
Visualize Simulations: See Details Above. Turns on Visualizations, and colors are randomly generated. Visualized max does not cap the calculated max. If 1000 simulations are used, the data will be from 1000 simulations, however only the last 99 simulations will be visualized.
Standard Deviation Multiplier: Sets the multiplier to use for the Standard Deviation distance away from the center line.
Monte Carlo Simulation - Your Strategy [Kioseff Trading]Hello!
This script “Monte Carlo Simulation - Your Strategy” uses Monte Carlo simulations for your inputted strategy returns or the asset on your chart!
Features
Monte Carlo Simulation: Performs Monte Carlo simulation to generate multiple future paths.
Asset Price or Strategy: Can simulate either future asset prices based on historical log returns or a specific trading strategy's future performance.
User-Defined Input: Allows you to input your own historical returns for simulation.
Statistical Methods: Offers two simulation methods—Gaussian (Normal) distribution and Bootstrapping.
Graphical Display: Provides options for graphical representation, including line plots and histograms.
Cumulative Probability Target: Enables setting a user-defined cumulative probability target to quantify simulation results.
Adjustable Parameters: Offers numerous user-adjustable settings like number of simulations, forecast length, and more.
Historical Data Points: Option to specify the amount of historical data to be used in the simulation (price).
Custom Binning: Allows you to select the binning method for histograms, with options like Sturges, Rice, and Square Root.
Best/Worst Case: Allows you to show only the best case / worst case outcome (range) for all simulations!
Scatterplot: allows you to show up to 1000 potential outcomes for a specified trade number (or bars forward price endpoint) using a scatter plot.
The image above shows the primary components of the indicator!
The image above shows the best/worst case outcome feature in action!
The image above shows a "fun feature" where 1000 simulated end points for a 15-bar price trajectory are shown as a scatter plot!
How To Perform a Monte Carlo Simulation On Your Strategy
Really, you can input any data into the indicator it will perform a Monte Carlo Simulation on it :D
The following instructions show how to export your strategy results from TradingView to an Excel File, copy the data, and input it into the indicator.
However , you are not limited to following this method!
Wherever your strategy results are stored, simply copy and paste them into the indicator text area in the settings and simulations will begin.
Returns Should Follow This Format
1
3
-3
2
-5
The numbers are presented as a single column. No commas or separators used.
The numbers above are in sequential order. A return of "1" for the first trade and a return of "-5" for the last trade. Your strategy returns will likely be in sequential order already so don't worry too much about this (:
How To Perform a Monte Carlo Simulation On Your TradingView Strategy With Excel Data
Export your strategy returns to an excel file using TradingView
Navigate to your downloads folder to column G "Profit"
Click the column and press CTRL + SPACE to highlight the entire column
Press CTRL + C to copy the entire column
Open this indicator's settings and paste the returns into the text area
The image above illustrates the process!
Notes on Inputting Returns
*Must input your returns without a separate as a vertical list
*The initial text area can only hold so many return values. If your list of trades is large you can input additional returns into two additional text areas at the bottom of the indicator settings.
That should be it; thank you for checking this out!

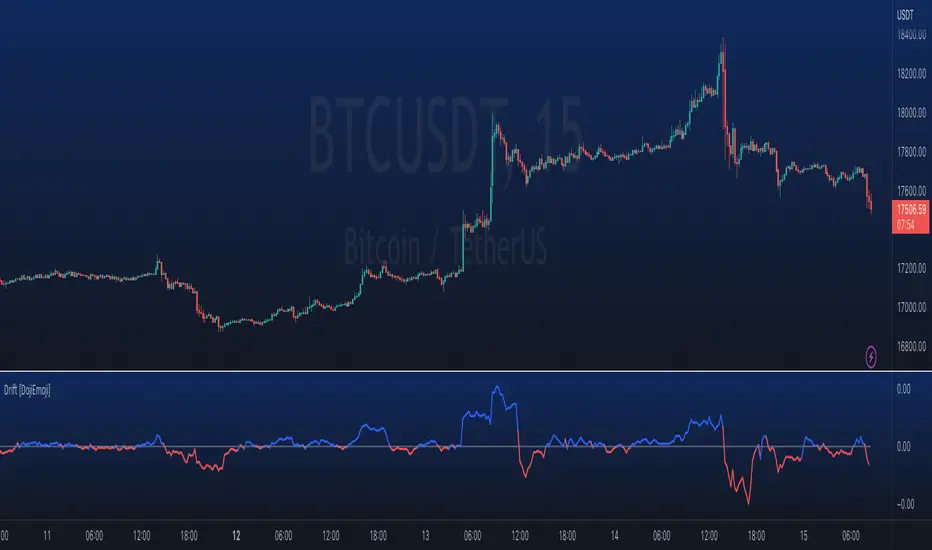
Drift Study (Inspired by Monte Carlo Simulations with BM) [KL]Inspired by the Brownian Motion ("BM") model that could be applied to conducting Monte Carlo Simulations, this indicator plots out the Drift factor contributing to BM.
Interpretation : If the Drift value is positive, then prices are possibly moving in an uptrend. Vice versa for negative drifts.
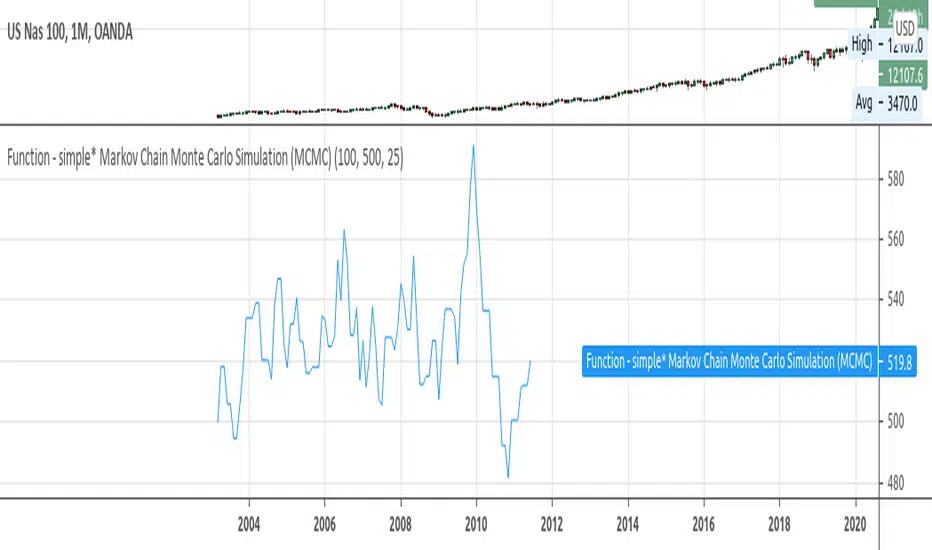
Function - simple* Markov Chain Monte Carlo Simulation (MCMC)Example function of a markov chain monte carlo simulation.
Monte Carlo Range Forecast [DW]This is an experimental study designed to forecast the range of price movement from a specified starting point using a Monte Carlo simulation.
Monte Carlo experiments are a broad class of computational algorithms that utilize random sampling to derive real world numerical results.
These types of algorithms have a number of applications in numerous fields of study including physics, engineering, behavioral sciences, climate forecasting, computer graphics, gaming AI, mathematics, and finance.
Although the applications vary, there is a typical process behind the majority of Monte Carlo methods:
-> First, a distribution of possible inputs is defined.
-> Next, values are generated randomly from the distribution.
-> The values are then fed through some form of deterministic algorithm.
-> And lastly, the results are aggregated over some number of iterations.
In this study, the Monte Carlo process used generates a distribution of aggregate pseudorandom linear price returns summed over a user defined period, then plots standard deviations of the outcomes from the mean outcome generate forecast regions.
The pseudorandom process used in this script relies on a modified Wichmann-Hill pseudorandom number generator (PRNG) algorithm.
Wichmann-Hill is a hybrid generator that uses three linear congruential generators (LCGs) with different prime moduli.
Each LCG within the generator produces an independent, uniformly distributed number between 0 and 1.
The three generated values are then summed and modulo 1 is taken to deliver the final uniformly distributed output.
Because of its long cycle length, Wichmann-Hill is a fantastic generator to use on TV since it's extremely unlikely that you'll ever see a cycle repeat.
The resulting pseudorandom output from this generator has a minimum repetition cycle length of 6,953,607,871,644.
Fun fact: Wichmann-Hill is a widely used PRNG in various software applications. For example, Excel 2003 and later uses this algorithm in its RAND function, and it was the default generator in Python up to v2.2.
The generation algorithm in this script takes the Wichmann-Hill algorithm, and uses a multi-stage transformation process to generate the results.
First, a parent seed is selected. This can either be a fixed value, or a dynamic value.
The dynamic parent value is produced by taking advantage of Pine's timenow variable behavior. It produces a variable parent seed by using a frozen ratio of timenow/time.
Because timenow always reflects the current real time when frozen and the time variable reflects the chart's beginning time when frozen, the ratio of these values produces a new number every time the cache updates.
After a parent seed is selected, its value is then fed through a uniformly distributed seed array generator, which generates multiple arrays of pseudorandom "children" seeds.
The seeds produced in this step are then fed through the main generators to produce arrays of pseudorandom simulated outcomes, and a pseudorandom series to compare with the real series.
The main generators within this script are designed to (at least somewhat) model the stochastic nature of financial time series data.
The first step in this process is to transform the uniform outputs of the Wichmann-Hill into outputs that are normally distributed.
In this script, the transformation is done using an estimate of the normal distribution quantile function.
Quantile functions, otherwise known as percent-point or inverse cumulative distribution functions, specify the value of a random variable such that the probability of the variable being within the value's boundary equals the input probability.
The quantile equation for a normal probability distribution is μ + σ(√2)erf^-1(2(p - 0.5)) where μ is the mean of the distribution, σ is the standard deviation, erf^-1 is the inverse Gauss error function, and p is the probability.
Because erf^-1() does not have a simple, closed form interpretation, it must be approximated.
To keep things lightweight in this approximation, I used a truncated Maclaurin Series expansion for this function with precomputed coefficients and rolled out operations to avoid nested looping.
This method provides a decent approximation of the error function without completely breaking floating point limits or sucking up runtime memory.
Note that there are plenty of more robust techniques to approximate this function, but their memory needs very. I chose this method specifically because of runtime favorability.
To generate a pseudorandom approximately normally distributed variable, the uniformly distributed variable from the Wichmann-Hill algorithm is used as the input probability for the quantile estimator.
Now from here, we get a pretty decent output that could be used itself in the simulation process. Many Monte Carlo simulations and random price generators utilize a normal variable.
However, if you compare the outputs of this normal variable with the actual returns of the real time series, you'll find that the variability in shocks (random changes) doesn't quite behave like it does in real data.
This is because most real financial time series data is more complex. Its distribution may be approximately normal at times, but the variability of its distribution changes over time due to various underlying factors.
In light of this, I believe that returns behave more like a convoluted product distribution rather than just a raw normal.
So the next step to get our procedurally generated returns to more closely emulate the behavior of real returns is to introduce more complexity into our model.
Through experimentation, I've found that a return series more closely emulating real returns can be generated in a three step process:
-> First, generate multiple independent, normally distributed variables simultaneously.
-> Next, apply pseudorandom weighting to each variable ranging from -1 to 1, or some limits within those bounds. This modulates each series to provide more variability in the shocks by producing product distributions.
-> Lastly, add the results together to generate the final pseudorandom output with a convoluted distribution. This adds variable amounts of constructive and destructive interference to produce a more "natural" looking output.
In this script, I use three independent normally distributed variables multiplied by uniform product distributed variables.
The first variable is generated by multiplying a normal variable by one uniformly distributed variable. This produces a bit more tailedness (kurtosis) than a normal distribution, but nothing too extreme.
The second variable is generated by multiplying a normal variable by two uniformly distributed variables. This produces moderately greater tails in the distribution.
The third variable is generated by multiplying a normal variable by three uniformly distributed variables. This produces a distribution with heavier tails.
For additional control of the output distributions, the uniform product distributions are given optional limits.
These limits control the boundaries for the absolute value of the uniform product variables, which affects the tails. In other words, they limit the weighting applied to the normally distributed variables in this transformation.
All three sets are then multiplied by user defined amplitude factors to adjust presence, then added together to produce our final pseudorandom return series with a convoluted product distribution.
Once we have the final, more "natural" looking pseudorandom series, the values are recursively summed over the forecast period to generate a simulated result.
This process of generation, weighting, addition, and summation is repeated over the user defined number of simulations with different seeds generated from the parent to produce our array of initial simulated outcomes.
After the initial simulation array is generated, the max, min, mean and standard deviation of this array are calculated, and the values are stored in holding arrays on each iteration to be called upon later.
Reference difference series and price values are also stored in holding arrays to be used in our comparison plots.
In this script, I use a linear model with simple returns rather than compounding log returns to generate the output.
The reason for this is that in generating outputs this way, we're able to run our simulations recursively from the beginning of the chart, then apply scaling and anchoring post-process.
This allows a greater conservation of runtime memory than the alternative, making it more suitable for doing longer forecasts with heavier amounts of simulations in TV's runtime environment.
From our starting time, the previous bar's price, volatility, and optional drift (expected return) are factored into our holding arrays to generate the final forecast parameters.
After these parameters are computed, the range forecast is produced.
The basis value for the ranges is the mean outcome of the simulations that were run.
Then, quarter standard deviations of the simulated outcomes are added to and subtracted from the basis up to 3σ to generate the forecast ranges.
All of these values are plotted and colorized based on their theoretical probability density. The most likely areas are the warmest colors, and least likely areas are the coolest colors.
An information panel is also displayed at the starting time which shows the starting time and price, forecast type, parent seed value, simulations run, forecast bars, total drift, mean, standard deviation, max outcome, min outcome, and bars remaining.
The interesting thing about simulated outcomes is that although the probability distribution of each simulation is not normal, the distribution of different outcomes converges to a normal one with enough steps.
In light of this, the probability density of outcomes is highest near the initial value + total drift, and decreases the further away from this point you go.
This makes logical sense since the central path is the easiest one to travel.
Given the ever changing state of markets, I find this tool to be best suited for shorter term forecasts.
However, if the movements of price are expected to remain relatively stable, longer term forecasts may be equally as valid.
There are many possible ways for users to apply this tool to their analysis setups. For example, the forecast ranges may be used as a guide to help users set risk targets.
Or, the generated levels could be used in conjunction with other indicators for meaningful confluence signals.
More advanced users could even extrapolate the functions used within this script for various purposes, such as generating pseudorandom data to test systems on, perform integration and approximations, etc.
These are just a few examples of potential uses of this script. How you choose to use it to benefit your trading, analysis, and coding is entirely up to you.
If nothing else, I think this is a pretty neat script simply for the novelty of it.
----------
How To Use:
When you first add the script to your chart, you will be prompted to confirm the starting date and time, number of bars to forecast, number of simulations to run, and whether to include drift assumption.
You will also be prompted to confirm the forecast type. There are two types to choose from:
-> End Result - This uses the values from the end of the simulation throughout the forecast interval.
-> Developing - This uses the values that develop from bar to bar, providing a real-time outlook.
You can always update these settings after confirmation as well.
Once these inputs are confirmed, the script will boot up and automatically generate the forecast in a separate pane.
Note that if there is no bar of data at the time you wish to start the forecast, the script will automatically detect use the next available bar after the specified start time.
From here, you can now control the rest of the settings.
The "Seeding Settings" section controls the initial seed value used to generate the children that produce the simulations.
In this section, you can control whether the seed is a fixed value, or a dynamic one.
Since selecting the dynamic parent option will change the seed value every time you change the settings or refresh your chart, there is a "Regenerate" input built into the script.
This input is a dummy input that isn't connected to any of the calculations. The purpose of this input is to force an update of the dynamic parent without affecting the generator or forecast settings.
Note that because we're running a limited number of simulations, different parent seeds will typically yield slightly different forecast ranges.
When using a small number of simulations, you will likely see a higher amount of variance between differently seeded results because smaller numbers of sampled simulations yield a heavier bias.
The more simulations you run, the smaller this variance will become since the outcomes become more convergent toward the same distribution, so the differences between differently seeded forecasts will become more marginal.
When using a dynamic parent, pay attention to the dispersion of ranges.
When you find a set of ranges that is dispersed how you like with your configuration, set your fixed parent value to the parent seed that shows in the info panel.
This will allow you to replicate that dispersion behavior again in the future.
An important thing to note when settings alerts on the plotted levels, or using them as components for signals in other scripts, is to decide on a fixed value for your parent seed to avoid minor repainting due to seed changes.
When the parent seed is fixed, no repainting occurs.
The "Amplitude Settings" section controls the amplitude coefficients for the three differently tailed generators.
These amplitude factors will change the difference series output for each simulation by controlling how aggressively each series moves.
When "Adjust Amplitude Coefficients" is disabled, all three coefficients are set to 1.
Note that if you expect volatility to significantly diverge from its historical values over the forecast interval, try experimenting with these factors to match your anticipation.
The "Weighting Settings" section controls the weighting boundaries for the three generators.
These weighting limits affect how tailed the distributions in each generator are, which in turn affects the final series outputs.
The maximum absolute value range for the weights is . When "Limit Generator Weights" is disabled, this is the range that is automatically used.
The last set of inputs is the "Display Settings", where you can control the visual outputs.
From here, you can select to display either "Forecast" or "Difference Comparison" via the "Output Display Type" dropdown tab.
"Forecast" is the type displayed by default. This plots the end result or developing forecast ranges.
There is an option with this display type to show the developing extremes of the simulations. This option is enabled by default.
There's also an option with this display type to show one of the simulated price series from the set alongside actual prices.
This allows you to visually compare simulated prices alongside the real prices.
"Difference Comparison" allows you to visually compare a synthetic difference series from the set alongside the actual difference series.
This display method is primarily useful for visually tuning the amplitude and weighting settings of the generators.
There are also info panel settings on the bottom, which allow you to control size, colors, and date format for the panel.
It's all pretty simple to use once you get the hang of it. So play around with the settings and see what kinds of forecasts you can generate!
----------
ADDITIONAL NOTES & DISCLAIMERS
Although I've done a number of things within this script to keep runtime demands as low as possible, the fact remains that this script is fairly computationally heavy.
Because of this, you may get random timeouts when using this script.
This could be due to either random drops in available runtime on the server, using too many simulations, or running the simulations over too many bars.
If it's just a random drop in runtime on the server, hide and unhide the script, re-add it to the chart, or simply refresh the page.
If the timeout persists after trying this, then you'll need to adjust your settings to a less demanding configuration.
Please note that no specific claims are being made in regards to this script's predictive accuracy.
It must be understood that this model is based on randomized price generation with assumed constant drift and dispersion from historical data before the starting point.
Models like these not consider the real world factors that may influence price movement (economic changes, seasonality, macro-trends, instrument hype, etc.), nor the changes in sample distribution that may occur.
In light of this, it's perfectly possible for price data to exceed even the most extreme simulated outcomes.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
When basing your trading decisions on any trading methodology or utility, predictive or not, you do so at your own risk.
No guarantee is being issued regarding the accuracy of this forecast model.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently and treated as "general case scenarios", forecast models like these may very well be potentially beneficial tools to have in the arsenal.

Monte Carlo Simulation - Random WalkHello All,
Monte Carlo Simulation is a model used to predict the probability of different outcomes when the intervention of random variables is present. it is used by professionals in such widely disparate fields as finance, project management etc. You can find many articles about Monte Carlo Simulation on the net.
In this script I tried to make Monte Carlo Simulation and "Random Walk". it calculates results over and over, each time using a different set of random values that is created using historical data (500 times by default) and show min-max and some random paths. number of "random walks" is calculated by using number of bars to predict, so if you change "Number of Bars to Predict" then number of random walks may change. Total number of the lines must be less than 500.
"Number of Simulations " is 500 by default, more simulation better results. but if you increase it a lot then you may get "loop takes too long error"
"Number of Bars to Predict" can be between 10-100
"Number of Bars to use as Data Source" is the number of historical bars to use in simulations
Thanks to Ricardo Santos (@RicardoSantos) for letting me use his Random Number Generator Function.
P.S. I am not mathematician and I tried to make it as far as I understood the method. so if you see any issue let me know please.
Some examples:
Number of Bars to Predict = 100:
Number of Bars to Predict = 10:
if you enable "Keep Past Min-Max Levels" option then min-max levels will stay on the chart
Enjoy!

Example: Monte Carlo SimulationExperimental:
Example execution of Monte Carlo Simulation applied to the markets(this is my interpretation of the algo so inconsistencys may appear).
note:
the algorithm is very demanding so performance is limited.