Editors' picksOPEN-SOURCE SCRIPT
Monte Carlo Range Forecast [DW]
Updated
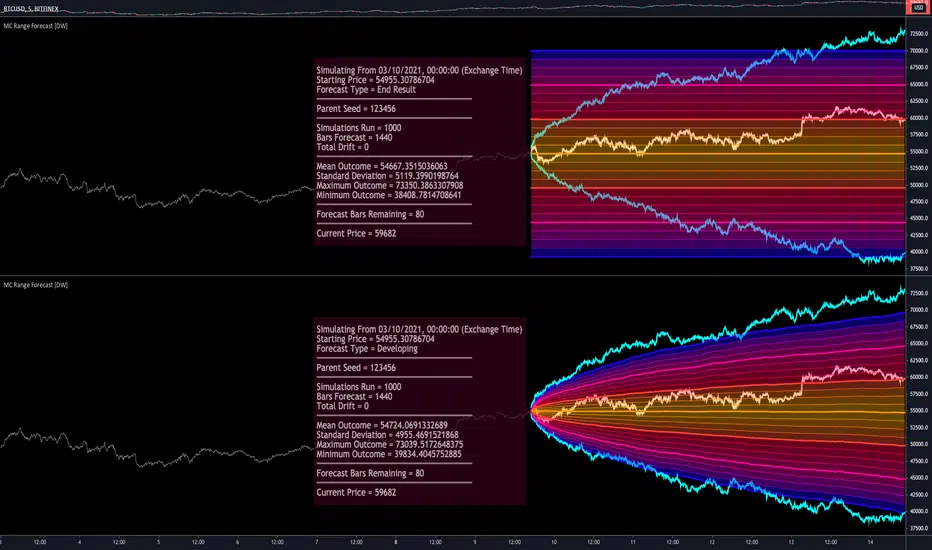
This is an experimental study designed to forecast the range of price movement from a specified starting point using a Monte Carlo simulation.
Monte Carlo experiments are a broad class of computational algorithms that utilize random sampling to derive real world numerical results.
These types of algorithms have a number of applications in numerous fields of study including physics, engineering, behavioral sciences, climate forecasting, computer graphics, gaming AI, mathematics, and finance.
Although the applications vary, there is a typical process behind the majority of Monte Carlo methods:
-> First, a distribution of possible inputs is defined.
-> Next, values are generated randomly from the distribution.
-> The values are then fed through some form of deterministic algorithm.
-> And lastly, the results are aggregated over some number of iterations.
In this study, the Monte Carlo process used generates a distribution of aggregate pseudorandom linear price returns summed over a user defined period, then plots standard deviations of the outcomes from the mean outcome generate forecast regions.
The pseudorandom process used in this script relies on a modified Wichmann-Hill pseudorandom number generator (PRNG) algorithm.
Wichmann-Hill is a hybrid generator that uses three linear congruential generators (LCGs) with different prime moduli.
Each LCG within the generator produces an independent, uniformly distributed number between 0 and 1.
The three generated values are then summed and modulo 1 is taken to deliver the final uniformly distributed output.
Because of its long cycle length, Wichmann-Hill is a fantastic generator to use on TV since it's extremely unlikely that you'll ever see a cycle repeat.
The resulting pseudorandom output from this generator has a minimum repetition cycle length of 6,953,607,871,644.
Fun fact: Wichmann-Hill is a widely used PRNG in various software applications. For example, Excel 2003 and later uses this algorithm in its RAND function, and it was the default generator in Python up to v2.2.
The generation algorithm in this script takes the Wichmann-Hill algorithm, and uses a multi-stage transformation process to generate the results.
First, a parent seed is selected. This can either be a fixed value, or a dynamic value.
The dynamic parent value is produced by taking advantage of Pine's timenow variable behavior. It produces a variable parent seed by using a frozen ratio of timenow/time.
Because timenow always reflects the current real time when frozen and the time variable reflects the chart's beginning time when frozen, the ratio of these values produces a new number every time the cache updates.
After a parent seed is selected, its value is then fed through a uniformly distributed seed array generator, which generates multiple arrays of pseudorandom "children" seeds.
The seeds produced in this step are then fed through the main generators to produce arrays of pseudorandom simulated outcomes, and a pseudorandom series to compare with the real series.
The main generators within this script are designed to (at least somewhat) model the stochastic nature of financial time series data.
The first step in this process is to transform the uniform outputs of the Wichmann-Hill into outputs that are normally distributed.
In this script, the transformation is done using an estimate of the normal distribution quantile function.
Quantile functions, otherwise known as percent-point or inverse cumulative distribution functions, specify the value of a random variable such that the probability of the variable being within the value's boundary equals the input probability.
The quantile equation for a normal probability distribution is μ + σ(√2)erf^-1(2(p - 0.5)) where μ is the mean of the distribution, σ is the standard deviation, erf^-1 is the inverse Gauss error function, and p is the probability.
Because erf^-1() does not have a simple, closed form interpretation, it must be approximated.
To keep things lightweight in this approximation, I used a truncated Maclaurin Series expansion for this function with precomputed coefficients and rolled out operations to avoid nested looping.
This method provides a decent approximation of the error function without completely breaking floating point limits or sucking up runtime memory.
Note that there are plenty of more robust techniques to approximate this function, but their memory needs very. I chose this method specifically because of runtime favorability.
To generate a pseudorandom approximately normally distributed variable, the uniformly distributed variable from the Wichmann-Hill algorithm is used as the input probability for the quantile estimator.
Now from here, we get a pretty decent output that could be used itself in the simulation process. Many Monte Carlo simulations and random price generators utilize a normal variable.
However, if you compare the outputs of this normal variable with the actual returns of the real time series, you'll find that the variability in shocks (random changes) doesn't quite behave like it does in real data.
This is because most real financial time series data is more complex. Its distribution may be approximately normal at times, but the variability of its distribution changes over time due to various underlying factors.
In light of this, I believe that returns behave more like a convoluted product distribution rather than just a raw normal.
So the next step to get our procedurally generated returns to more closely emulate the behavior of real returns is to introduce more complexity into our model.
Through experimentation, I've found that a return series more closely emulating real returns can be generated in a three step process:
-> First, generate multiple independent, normally distributed variables simultaneously.
-> Next, apply pseudorandom weighting to each variable ranging from -1 to 1, or some limits within those bounds. This modulates each series to provide more variability in the shocks by producing product distributions.
-> Lastly, add the results together to generate the final pseudorandom output with a convoluted distribution. This adds variable amounts of constructive and destructive interference to produce a more "natural" looking output.
In this script, I use three independent normally distributed variables multiplied by uniform product distributed variables.
The first variable is generated by multiplying a normal variable by one uniformly distributed variable. This produces a bit more tailedness (kurtosis) than a normal distribution, but nothing too extreme.
The second variable is generated by multiplying a normal variable by two uniformly distributed variables. This produces moderately greater tails in the distribution.
The third variable is generated by multiplying a normal variable by three uniformly distributed variables. This produces a distribution with heavier tails.
For additional control of the output distributions, the uniform product distributions are given optional limits.
These limits control the boundaries for the absolute value of the uniform product variables, which affects the tails. In other words, they limit the weighting applied to the normally distributed variables in this transformation.
All three sets are then multiplied by user defined amplitude factors to adjust presence, then added together to produce our final pseudorandom return series with a convoluted product distribution.
Once we have the final, more "natural" looking pseudorandom series, the values are recursively summed over the forecast period to generate a simulated result.
This process of generation, weighting, addition, and summation is repeated over the user defined number of simulations with different seeds generated from the parent to produce our array of initial simulated outcomes.
After the initial simulation array is generated, the max, min, mean and standard deviation of this array are calculated, and the values are stored in holding arrays on each iteration to be called upon later.
Reference difference series and price values are also stored in holding arrays to be used in our comparison plots.
In this script, I use a linear model with simple returns rather than compounding log returns to generate the output.
The reason for this is that in generating outputs this way, we're able to run our simulations recursively from the beginning of the chart, then apply scaling and anchoring post-process.
This allows a greater conservation of runtime memory than the alternative, making it more suitable for doing longer forecasts with heavier amounts of simulations in TV's runtime environment.
From our starting time, the previous bar's price, volatility, and optional drift (expected return) are factored into our holding arrays to generate the final forecast parameters.
After these parameters are computed, the range forecast is produced.
The basis value for the ranges is the mean outcome of the simulations that were run.
Then, quarter standard deviations of the simulated outcomes are added to and subtracted from the basis up to 3σ to generate the forecast ranges.
All of these values are plotted and colorized based on their theoretical probability density. The most likely areas are the warmest colors, and least likely areas are the coolest colors.
An information panel is also displayed at the starting time which shows the starting time and price, forecast type, parent seed value, simulations run, forecast bars, total drift, mean, standard deviation, max outcome, min outcome, and bars remaining.
The interesting thing about simulated outcomes is that although the probability distribution of each simulation is not normal, the distribution of different outcomes converges to a normal one with enough steps.
In light of this, the probability density of outcomes is highest near the initial value + total drift, and decreases the further away from this point you go.
This makes logical sense since the central path is the easiest one to travel.
Given the ever changing state of markets, I find this tool to be best suited for shorter term forecasts.
However, if the movements of price are expected to remain relatively stable, longer term forecasts may be equally as valid.
There are many possible ways for users to apply this tool to their analysis setups. For example, the forecast ranges may be used as a guide to help users set risk targets.
Or, the generated levels could be used in conjunction with other indicators for meaningful confluence signals.
More advanced users could even extrapolate the functions used within this script for various purposes, such as generating pseudorandom data to test systems on, perform integration and approximations, etc.
These are just a few examples of potential uses of this script. How you choose to use it to benefit your trading, analysis, and coding is entirely up to you.
If nothing else, I think this is a pretty neat script simply for the novelty of it.
----------
How To Use:
When you first add the script to your chart, you will be prompted to confirm the starting date and time, number of bars to forecast, number of simulations to run, and whether to include drift assumption.
You will also be prompted to confirm the forecast type. There are two types to choose from:
-> End Result - This uses the values from the end of the simulation throughout the forecast interval.
-> Developing - This uses the values that develop from bar to bar, providing a real-time outlook.
You can always update these settings after confirmation as well.
Once these inputs are confirmed, the script will boot up and automatically generate the forecast in a separate pane.
Note that if there is no bar of data at the time you wish to start the forecast, the script will automatically detect use the next available bar after the specified start time.
From here, you can now control the rest of the settings.
The "Seeding Settings" section controls the initial seed value used to generate the children that produce the simulations.
In this section, you can control whether the seed is a fixed value, or a dynamic one.
Since selecting the dynamic parent option will change the seed value every time you change the settings or refresh your chart, there is a "Regenerate" input built into the script.
This input is a dummy input that isn't connected to any of the calculations. The purpose of this input is to force an update of the dynamic parent without affecting the generator or forecast settings.
Note that because we're running a limited number of simulations, different parent seeds will typically yield slightly different forecast ranges.
When using a small number of simulations, you will likely see a higher amount of variance between differently seeded results because smaller numbers of sampled simulations yield a heavier bias.
The more simulations you run, the smaller this variance will become since the outcomes become more convergent toward the same distribution, so the differences between differently seeded forecasts will become more marginal.
When using a dynamic parent, pay attention to the dispersion of ranges.
When you find a set of ranges that is dispersed how you like with your configuration, set your fixed parent value to the parent seed that shows in the info panel.
This will allow you to replicate that dispersion behavior again in the future.
An important thing to note when settings alerts on the plotted levels, or using them as components for signals in other scripts, is to decide on a fixed value for your parent seed to avoid minor repainting due to seed changes.
When the parent seed is fixed, no repainting occurs.
The "Amplitude Settings" section controls the amplitude coefficients for the three differently tailed generators.
These amplitude factors will change the difference series output for each simulation by controlling how aggressively each series moves.
When "Adjust Amplitude Coefficients" is disabled, all three coefficients are set to 1.
Note that if you expect volatility to significantly diverge from its historical values over the forecast interval, try experimenting with these factors to match your anticipation.
The "Weighting Settings" section controls the weighting boundaries for the three generators.
These weighting limits affect how tailed the distributions in each generator are, which in turn affects the final series outputs.
The maximum absolute value range for the weights is [0, 1]. When "Limit Generator Weights" is disabled, this is the range that is automatically used.
The last set of inputs is the "Display Settings", where you can control the visual outputs.
From here, you can select to display either "Forecast" or "Difference Comparison" via the "Output Display Type" dropdown tab.
"Forecast" is the type displayed by default. This plots the end result or developing forecast ranges.
There is an option with this display type to show the developing extremes of the simulations. This option is enabled by default.
There's also an option with this display type to show one of the simulated price series from the set alongside actual prices.
This allows you to visually compare simulated prices alongside the real prices.
"Difference Comparison" allows you to visually compare a synthetic difference series from the set alongside the actual difference series.
This display method is primarily useful for visually tuning the amplitude and weighting settings of the generators.
There are also info panel settings on the bottom, which allow you to control size, colors, and date format for the panel.
It's all pretty simple to use once you get the hang of it. So play around with the settings and see what kinds of forecasts you can generate!
----------
ADDITIONAL NOTES & DISCLAIMERS
Although I've done a number of things within this script to keep runtime demands as low as possible, the fact remains that this script is fairly computationally heavy.
Because of this, you may get random timeouts when using this script.
This could be due to either random drops in available runtime on the server, using too many simulations, or running the simulations over too many bars.
If it's just a random drop in runtime on the server, hide and unhide the script, re-add it to the chart, or simply refresh the page.
If the timeout persists after trying this, then you'll need to adjust your settings to a less demanding configuration.
Please note that no specific claims are being made in regards to this script's predictive accuracy.
It must be understood that this model is based on randomized price generation with assumed constant drift and dispersion from historical data before the starting point.
Models like these not consider the real world factors that may influence price movement (economic changes, seasonality, macro-trends, instrument hype, etc.), nor the changes in sample distribution that may occur.
In light of this, it's perfectly possible for price data to exceed even the most extreme simulated outcomes.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
When basing your trading decisions on any trading methodology or utility, predictive or not, you do so at your own risk.
No guarantee is being issued regarding the accuracy of this forecast model.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently and treated as "general case scenarios", forecast models like these may very well be potentially beneficial tools to have in the arsenal.
Monte Carlo experiments are a broad class of computational algorithms that utilize random sampling to derive real world numerical results.
These types of algorithms have a number of applications in numerous fields of study including physics, engineering, behavioral sciences, climate forecasting, computer graphics, gaming AI, mathematics, and finance.
Although the applications vary, there is a typical process behind the majority of Monte Carlo methods:
-> First, a distribution of possible inputs is defined.
-> Next, values are generated randomly from the distribution.
-> The values are then fed through some form of deterministic algorithm.
-> And lastly, the results are aggregated over some number of iterations.
In this study, the Monte Carlo process used generates a distribution of aggregate pseudorandom linear price returns summed over a user defined period, then plots standard deviations of the outcomes from the mean outcome generate forecast regions.
The pseudorandom process used in this script relies on a modified Wichmann-Hill pseudorandom number generator (PRNG) algorithm.
Wichmann-Hill is a hybrid generator that uses three linear congruential generators (LCGs) with different prime moduli.
Each LCG within the generator produces an independent, uniformly distributed number between 0 and 1.
The three generated values are then summed and modulo 1 is taken to deliver the final uniformly distributed output.
Because of its long cycle length, Wichmann-Hill is a fantastic generator to use on TV since it's extremely unlikely that you'll ever see a cycle repeat.
The resulting pseudorandom output from this generator has a minimum repetition cycle length of 6,953,607,871,644.
Fun fact: Wichmann-Hill is a widely used PRNG in various software applications. For example, Excel 2003 and later uses this algorithm in its RAND function, and it was the default generator in Python up to v2.2.
The generation algorithm in this script takes the Wichmann-Hill algorithm, and uses a multi-stage transformation process to generate the results.
First, a parent seed is selected. This can either be a fixed value, or a dynamic value.
The dynamic parent value is produced by taking advantage of Pine's timenow variable behavior. It produces a variable parent seed by using a frozen ratio of timenow/time.
Because timenow always reflects the current real time when frozen and the time variable reflects the chart's beginning time when frozen, the ratio of these values produces a new number every time the cache updates.
After a parent seed is selected, its value is then fed through a uniformly distributed seed array generator, which generates multiple arrays of pseudorandom "children" seeds.
The seeds produced in this step are then fed through the main generators to produce arrays of pseudorandom simulated outcomes, and a pseudorandom series to compare with the real series.
The main generators within this script are designed to (at least somewhat) model the stochastic nature of financial time series data.
The first step in this process is to transform the uniform outputs of the Wichmann-Hill into outputs that are normally distributed.
In this script, the transformation is done using an estimate of the normal distribution quantile function.
Quantile functions, otherwise known as percent-point or inverse cumulative distribution functions, specify the value of a random variable such that the probability of the variable being within the value's boundary equals the input probability.
The quantile equation for a normal probability distribution is μ + σ(√2)erf^-1(2(p - 0.5)) where μ is the mean of the distribution, σ is the standard deviation, erf^-1 is the inverse Gauss error function, and p is the probability.
Because erf^-1() does not have a simple, closed form interpretation, it must be approximated.
To keep things lightweight in this approximation, I used a truncated Maclaurin Series expansion for this function with precomputed coefficients and rolled out operations to avoid nested looping.
This method provides a decent approximation of the error function without completely breaking floating point limits or sucking up runtime memory.
Note that there are plenty of more robust techniques to approximate this function, but their memory needs very. I chose this method specifically because of runtime favorability.
To generate a pseudorandom approximately normally distributed variable, the uniformly distributed variable from the Wichmann-Hill algorithm is used as the input probability for the quantile estimator.
Now from here, we get a pretty decent output that could be used itself in the simulation process. Many Monte Carlo simulations and random price generators utilize a normal variable.
However, if you compare the outputs of this normal variable with the actual returns of the real time series, you'll find that the variability in shocks (random changes) doesn't quite behave like it does in real data.
This is because most real financial time series data is more complex. Its distribution may be approximately normal at times, but the variability of its distribution changes over time due to various underlying factors.
In light of this, I believe that returns behave more like a convoluted product distribution rather than just a raw normal.
So the next step to get our procedurally generated returns to more closely emulate the behavior of real returns is to introduce more complexity into our model.
Through experimentation, I've found that a return series more closely emulating real returns can be generated in a three step process:
-> First, generate multiple independent, normally distributed variables simultaneously.
-> Next, apply pseudorandom weighting to each variable ranging from -1 to 1, or some limits within those bounds. This modulates each series to provide more variability in the shocks by producing product distributions.
-> Lastly, add the results together to generate the final pseudorandom output with a convoluted distribution. This adds variable amounts of constructive and destructive interference to produce a more "natural" looking output.
In this script, I use three independent normally distributed variables multiplied by uniform product distributed variables.
The first variable is generated by multiplying a normal variable by one uniformly distributed variable. This produces a bit more tailedness (kurtosis) than a normal distribution, but nothing too extreme.
The second variable is generated by multiplying a normal variable by two uniformly distributed variables. This produces moderately greater tails in the distribution.
The third variable is generated by multiplying a normal variable by three uniformly distributed variables. This produces a distribution with heavier tails.
For additional control of the output distributions, the uniform product distributions are given optional limits.
These limits control the boundaries for the absolute value of the uniform product variables, which affects the tails. In other words, they limit the weighting applied to the normally distributed variables in this transformation.
All three sets are then multiplied by user defined amplitude factors to adjust presence, then added together to produce our final pseudorandom return series with a convoluted product distribution.
Once we have the final, more "natural" looking pseudorandom series, the values are recursively summed over the forecast period to generate a simulated result.
This process of generation, weighting, addition, and summation is repeated over the user defined number of simulations with different seeds generated from the parent to produce our array of initial simulated outcomes.
After the initial simulation array is generated, the max, min, mean and standard deviation of this array are calculated, and the values are stored in holding arrays on each iteration to be called upon later.
Reference difference series and price values are also stored in holding arrays to be used in our comparison plots.
In this script, I use a linear model with simple returns rather than compounding log returns to generate the output.
The reason for this is that in generating outputs this way, we're able to run our simulations recursively from the beginning of the chart, then apply scaling and anchoring post-process.
This allows a greater conservation of runtime memory than the alternative, making it more suitable for doing longer forecasts with heavier amounts of simulations in TV's runtime environment.
From our starting time, the previous bar's price, volatility, and optional drift (expected return) are factored into our holding arrays to generate the final forecast parameters.
After these parameters are computed, the range forecast is produced.
The basis value for the ranges is the mean outcome of the simulations that were run.
Then, quarter standard deviations of the simulated outcomes are added to and subtracted from the basis up to 3σ to generate the forecast ranges.
All of these values are plotted and colorized based on their theoretical probability density. The most likely areas are the warmest colors, and least likely areas are the coolest colors.
An information panel is also displayed at the starting time which shows the starting time and price, forecast type, parent seed value, simulations run, forecast bars, total drift, mean, standard deviation, max outcome, min outcome, and bars remaining.
The interesting thing about simulated outcomes is that although the probability distribution of each simulation is not normal, the distribution of different outcomes converges to a normal one with enough steps.
In light of this, the probability density of outcomes is highest near the initial value + total drift, and decreases the further away from this point you go.
This makes logical sense since the central path is the easiest one to travel.
Given the ever changing state of markets, I find this tool to be best suited for shorter term forecasts.
However, if the movements of price are expected to remain relatively stable, longer term forecasts may be equally as valid.
There are many possible ways for users to apply this tool to their analysis setups. For example, the forecast ranges may be used as a guide to help users set risk targets.
Or, the generated levels could be used in conjunction with other indicators for meaningful confluence signals.
More advanced users could even extrapolate the functions used within this script for various purposes, such as generating pseudorandom data to test systems on, perform integration and approximations, etc.
These are just a few examples of potential uses of this script. How you choose to use it to benefit your trading, analysis, and coding is entirely up to you.
If nothing else, I think this is a pretty neat script simply for the novelty of it.
----------
How To Use:
When you first add the script to your chart, you will be prompted to confirm the starting date and time, number of bars to forecast, number of simulations to run, and whether to include drift assumption.
You will also be prompted to confirm the forecast type. There are two types to choose from:
-> End Result - This uses the values from the end of the simulation throughout the forecast interval.
-> Developing - This uses the values that develop from bar to bar, providing a real-time outlook.
You can always update these settings after confirmation as well.
Once these inputs are confirmed, the script will boot up and automatically generate the forecast in a separate pane.
Note that if there is no bar of data at the time you wish to start the forecast, the script will automatically detect use the next available bar after the specified start time.
From here, you can now control the rest of the settings.
The "Seeding Settings" section controls the initial seed value used to generate the children that produce the simulations.
In this section, you can control whether the seed is a fixed value, or a dynamic one.
Since selecting the dynamic parent option will change the seed value every time you change the settings or refresh your chart, there is a "Regenerate" input built into the script.
This input is a dummy input that isn't connected to any of the calculations. The purpose of this input is to force an update of the dynamic parent without affecting the generator or forecast settings.
Note that because we're running a limited number of simulations, different parent seeds will typically yield slightly different forecast ranges.
When using a small number of simulations, you will likely see a higher amount of variance between differently seeded results because smaller numbers of sampled simulations yield a heavier bias.
The more simulations you run, the smaller this variance will become since the outcomes become more convergent toward the same distribution, so the differences between differently seeded forecasts will become more marginal.
When using a dynamic parent, pay attention to the dispersion of ranges.
When you find a set of ranges that is dispersed how you like with your configuration, set your fixed parent value to the parent seed that shows in the info panel.
This will allow you to replicate that dispersion behavior again in the future.
An important thing to note when settings alerts on the plotted levels, or using them as components for signals in other scripts, is to decide on a fixed value for your parent seed to avoid minor repainting due to seed changes.
When the parent seed is fixed, no repainting occurs.
The "Amplitude Settings" section controls the amplitude coefficients for the three differently tailed generators.
These amplitude factors will change the difference series output for each simulation by controlling how aggressively each series moves.
When "Adjust Amplitude Coefficients" is disabled, all three coefficients are set to 1.
Note that if you expect volatility to significantly diverge from its historical values over the forecast interval, try experimenting with these factors to match your anticipation.
The "Weighting Settings" section controls the weighting boundaries for the three generators.
These weighting limits affect how tailed the distributions in each generator are, which in turn affects the final series outputs.
The maximum absolute value range for the weights is [0, 1]. When "Limit Generator Weights" is disabled, this is the range that is automatically used.
The last set of inputs is the "Display Settings", where you can control the visual outputs.
From here, you can select to display either "Forecast" or "Difference Comparison" via the "Output Display Type" dropdown tab.
"Forecast" is the type displayed by default. This plots the end result or developing forecast ranges.
There is an option with this display type to show the developing extremes of the simulations. This option is enabled by default.
There's also an option with this display type to show one of the simulated price series from the set alongside actual prices.
This allows you to visually compare simulated prices alongside the real prices.
"Difference Comparison" allows you to visually compare a synthetic difference series from the set alongside the actual difference series.
This display method is primarily useful for visually tuning the amplitude and weighting settings of the generators.
There are also info panel settings on the bottom, which allow you to control size, colors, and date format for the panel.
It's all pretty simple to use once you get the hang of it. So play around with the settings and see what kinds of forecasts you can generate!
----------
ADDITIONAL NOTES & DISCLAIMERS
Although I've done a number of things within this script to keep runtime demands as low as possible, the fact remains that this script is fairly computationally heavy.
Because of this, you may get random timeouts when using this script.
This could be due to either random drops in available runtime on the server, using too many simulations, or running the simulations over too many bars.
If it's just a random drop in runtime on the server, hide and unhide the script, re-add it to the chart, or simply refresh the page.
If the timeout persists after trying this, then you'll need to adjust your settings to a less demanding configuration.
Please note that no specific claims are being made in regards to this script's predictive accuracy.
It must be understood that this model is based on randomized price generation with assumed constant drift and dispersion from historical data before the starting point.
Models like these not consider the real world factors that may influence price movement (economic changes, seasonality, macro-trends, instrument hype, etc.), nor the changes in sample distribution that may occur.
In light of this, it's perfectly possible for price data to exceed even the most extreme simulated outcomes.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
When basing your trading decisions on any trading methodology or utility, predictive or not, you do so at your own risk.
No guarantee is being issued regarding the accuracy of this forecast model.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently and treated as "general case scenarios", forecast models like these may very well be potentially beneficial tools to have in the arsenal.
Release Notes
Updates:- Updated the inverse error function approximation. The previous truncated Maclaurin Series based approximation was a bit too crude for my liking.
It's now based on inverting a close approximation of the error function. This method has much less estimation error, and significantly more tail preservation.
Fortunately, this approximation method doesn't make a significantly larger dent in runtime consumption, so you should still be able to enjoy the forecast configurations you had in the previous version.
- Added a price tracking field to the bottom of the info panel.
When there are bars remaining in the forecast, the panel will say, "Current Price = xxx," where xxx is the real time current price value.
When the forecast interval is completed, the panel will say, "Final Price = xxx," where xxx is the final price on the last bar of the forecast interval.
Please note that once you load your chart with this updated version, it will replace the previous version and override your previous settings if you have it on the chart already.
So, be sure to either re-add the script to your chart, or reconfigure your forecast settings.
Open-source script
In true TradingView spirit, the author of this script has published it open-source, so traders can understand and verify it. Cheers to the author! You may use it for free, but reuse of this code in publication is governed by House rules. You can favorite it to use it on a chart.
Want to use this script on a chart?
For my full list of premium tools, check the blog:
wallanalytics.com/
Reach out on Telegram:
t.me/DonovanWall
wallanalytics.com/
Reach out on Telegram:
t.me/DonovanWall
Disclaimer
The information and publications are not meant to be, and do not constitute, financial, investment, trading, or other types of advice or recommendations supplied or endorsed by TradingView. Read more in the Terms of Use.