Machine Learning: kNN (New Approach)
Updated
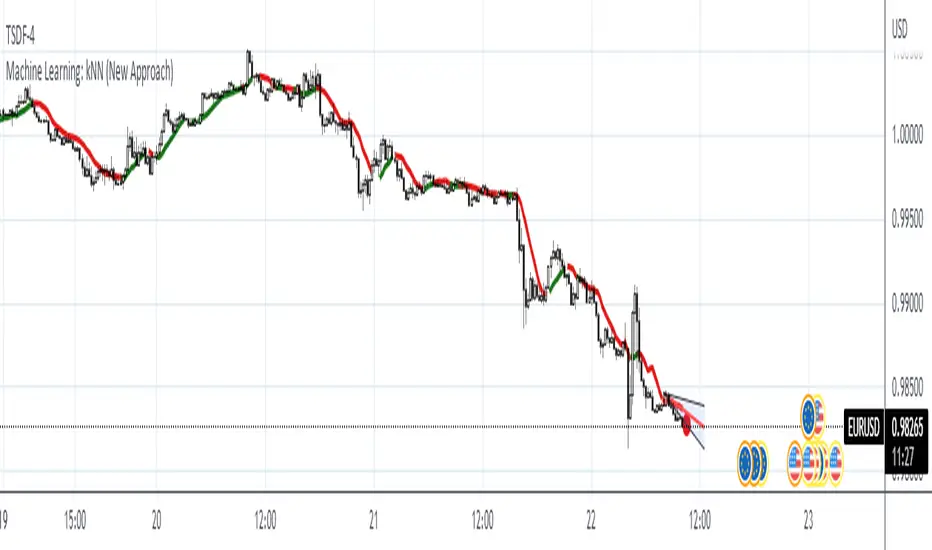
Description:
kNN is a very robust and simple method for data classification and prediction. It is very effective if the training data is large. However, it is distinguished by difficulty at determining its main parameter, K (a number of nearest neighbors), beforehand. The computation cost is also quite high because we need to compute distance of each instance to all training samples. Nevertheless, in algorithmic trading KNN is reported to perform on a par with such techniques as SVM and Random Forest. It is also widely used in the area of data science.
The input data is just a long series of prices over time without any particular features. The value to be predicted is just the next bar's price. The way that this problem is solved for both nearest neighbor techniques and for some other types of prediction algorithms is to create training records by taking, for instance, 10 consecutive prices and using the first 9 as predictor values and the 10th as the prediction value. Doing this way, given 100 data points in your time series you could create 10 different training records. It's possible to create even more training records than 10 by creating a new record starting at every data point. For instance, you could take the first 10 data points and create a record. Then you could take the 10 consecutive data points starting at the second data point, the 10 consecutive data points starting at the third data point, etc.
By default, shown are only 10 initial data points as predictor values and the 6th as the prediction value.
Here is a step-by-step workthrough on how to compute K nearest neighbors (KNN) algorithm for quantitative data:
1. Determine parameter K = number of nearest neighbors.
2. Calculate the distance between the instance and all the training samples. As we are dealing with one-dimensional distance, we simply take absolute value from the instance to value of x (| x – v |).
3. Rank the distance and determine nearest neighbors based on the K'th minimum distance.
4. Gather the values of the nearest neighbors.
5. Use average of nearest neighbors as the prediction value of the instance.
The original logic of the algorithm was slightly modified, and as a result at approx. N=17 the resulting curve nicely approximates that of the sma(20). See the description below. Beside the sma-like MA this algorithm also gives you a hint on the direction of the next bar move.
kNN is a very robust and simple method for data classification and prediction. It is very effective if the training data is large. However, it is distinguished by difficulty at determining its main parameter, K (a number of nearest neighbors), beforehand. The computation cost is also quite high because we need to compute distance of each instance to all training samples. Nevertheless, in algorithmic trading KNN is reported to perform on a par with such techniques as SVM and Random Forest. It is also widely used in the area of data science.
The input data is just a long series of prices over time without any particular features. The value to be predicted is just the next bar's price. The way that this problem is solved for both nearest neighbor techniques and for some other types of prediction algorithms is to create training records by taking, for instance, 10 consecutive prices and using the first 9 as predictor values and the 10th as the prediction value. Doing this way, given 100 data points in your time series you could create 10 different training records. It's possible to create even more training records than 10 by creating a new record starting at every data point. For instance, you could take the first 10 data points and create a record. Then you could take the 10 consecutive data points starting at the second data point, the 10 consecutive data points starting at the third data point, etc.
By default, shown are only 10 initial data points as predictor values and the 6th as the prediction value.
Here is a step-by-step workthrough on how to compute K nearest neighbors (KNN) algorithm for quantitative data:
1. Determine parameter K = number of nearest neighbors.
2. Calculate the distance between the instance and all the training samples. As we are dealing with one-dimensional distance, we simply take absolute value from the instance to value of x (| x – v |).
3. Rank the distance and determine nearest neighbors based on the K'th minimum distance.
4. Gather the values of the nearest neighbors.
5. Use average of nearest neighbors as the prediction value of the instance.
The original logic of the algorithm was slightly modified, and as a result at approx. N=17 the resulting curve nicely approximates that of the sma(20). See the description below. Beside the sma-like MA this algorithm also gives you a hint on the direction of the next bar move.
Release Notes
Minor fix.Release Notes
Minor fix.Open-source script
In true TradingView spirit, the author of this script has published it open-source, so traders can understand and verify it. Cheers to the author! You may use it for free, but reuse of this code in publication is governed by House rules. You can favorite it to use it on a chart.
Want to use this script on a chart?
Disclaimer
The information and publications are not meant to be, and do not constitute, financial, investment, trading, or other types of advice or recommendations supplied or endorsed by TradingView. Read more in the Terms of Use.